
Adding a dataset from HDFS
You can access data stored on HDFS (Hadoop File System), directly from the
Talend Data Preparation
interface and import it in the form of a dataset.
Procedure
-
Select HDFS.
The Add an HDFS dataset form opens.
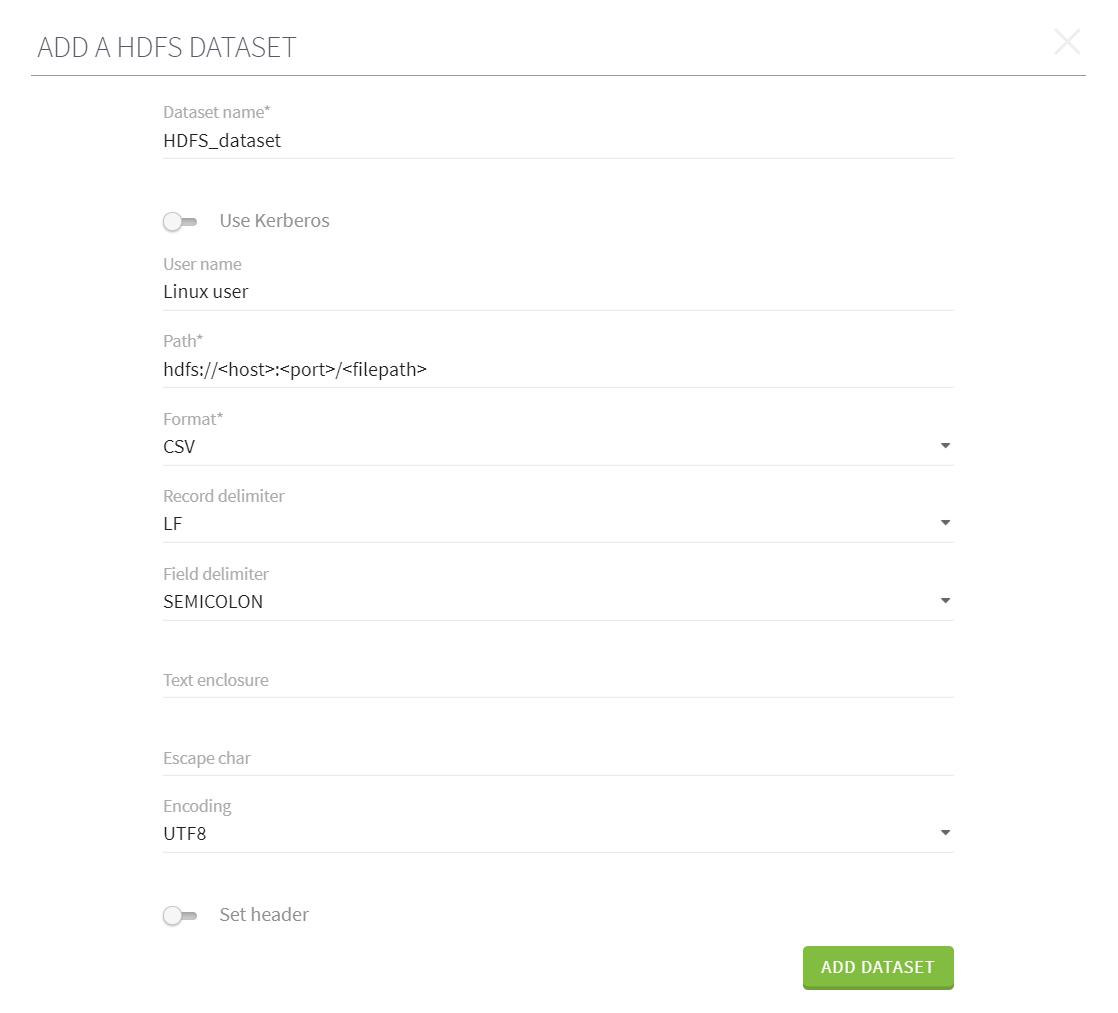
-
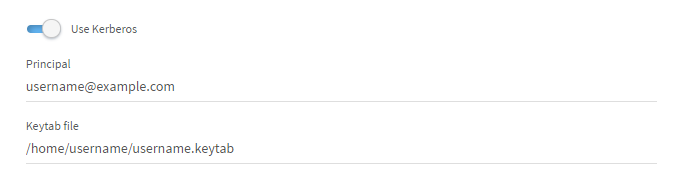
To enable Kerberos authentication, select the Use
Kerberos check box.
Results
The data extracted from the cluster directly opens in the grid and you can start working on your preparation.
The data is still stored in the cluster and doesn't leave it, Talend Data Preparation only retrieves a sample on-demand.
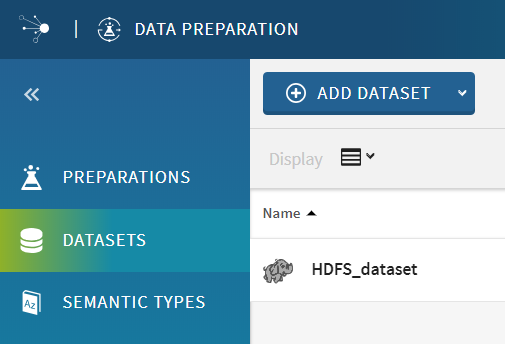
Your dataset is now available in the Datasets view of the application home page.
Did this page help you?
If you find any issues with this page or its content – a typo, a missing step, or a technical error – let us know how we can improve!