
How to handle mixed encoding in MapReduce Jobs
When the source data you need to read from HDFS contains mixed encoding, for example, UTF-8 with the delimiter in ISO-8859-15, you need to activate the related feature provided by the tHDFSInput component to help read the data.
The Activate advanced decoder check box has been added to the Advanced settings tab of the MapReduce version of the tHDFSInput component to handle mixed encoding.
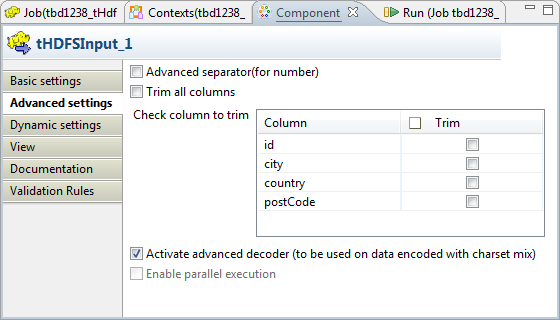
The procedure described in this article is to explain this Activate advanced decoder feature only. Activating this feature alone does not allow your MapReduce Job to run successfully. You still need to properly design your Job and configure the connection to the Hadoop cluster to be used.
This feature requires one of the mixed encoding types to be UTF-8.
The following table presents the encoding types which this feature has been tested to be able to successfully handle while the default decoder of tHDFSInput fails to.
| Principal encoding | Delimiter encoding | Default decoder | Advanced decoder | Comment |
| UTF-8 | ISO-8859-15 |
|
|
The delimiter used is the thor letter ( þ ). |
| ISO-8859-15 | UTF-8 |
|
|
The delimiter used is the thor letter ( þ ). |
Before you begin
-
One of the subscription-based Talend solutions with Big Data.
Procedure
-
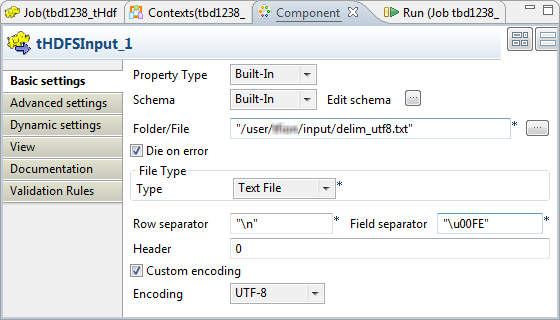
Double-click tHDFSInput to open its Basic settings tab.
Example
Results
Now this tHDFSInput component is able to read mixed encoding.
For further information about the other parameters of tHDFSInput, see .