
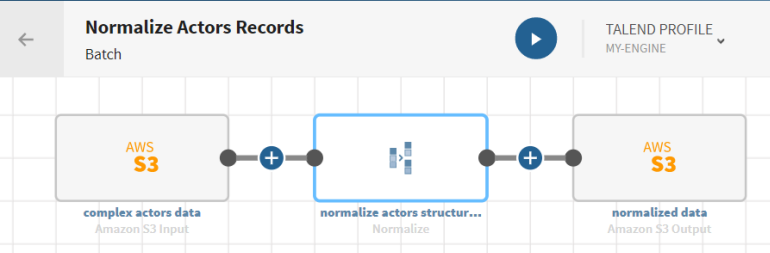
Normalizing complex records
Before you begin
-
You have previously created a connection to the system storing your source data.
Here, an Amazon S3 connection.
-
You have previously added the dataset holding your source data.
Here, hierarchical data about actors including ID, name, country, etc.
-
You also have created the connection and the related dataset that will hold the processed data.
Here, a file stored on Amazon S3.
Procedure
-
Click
 and add a Normalize processor to the pipeline. The
Configuration panel opens.
and add a Normalize processor to the pipeline. The
Configuration panel opens.
-
(Optional) Look at the preview of the Normalize processor to compare your data before and after the normalizing operation.
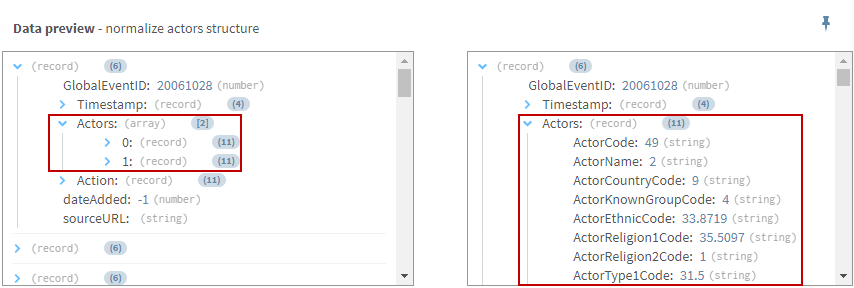
Results
Your pipeline is being executed, the records are normalized and the output is sent to the target system you have indicated.
Did this page help you?
If you find any issues with this page or its content – a typo, a missing step, or a technical error – let us know how we can improve!