
Big Data
|
Feature |
Description |
Available in |
|---|---|---|
| Support for Amazon EMR 6.6.0 and 6.7.0 with Spark Universal 3.2.x |
You can now run your Spark Jobs on an Amazon EMR cluster using Spark Universal with Spark 3.2.x in Yarn cluster mode. You can configure it either in the Spark Configuration view of your Spark Jobs or in the Hadoop Cluster Connection metadata wizard. When you select this mode, Talend Studio is compatible with Amazon EMR 6.6.0 and 6.7.0 versions. |
All subscription-based Talend products with Big Data |
|
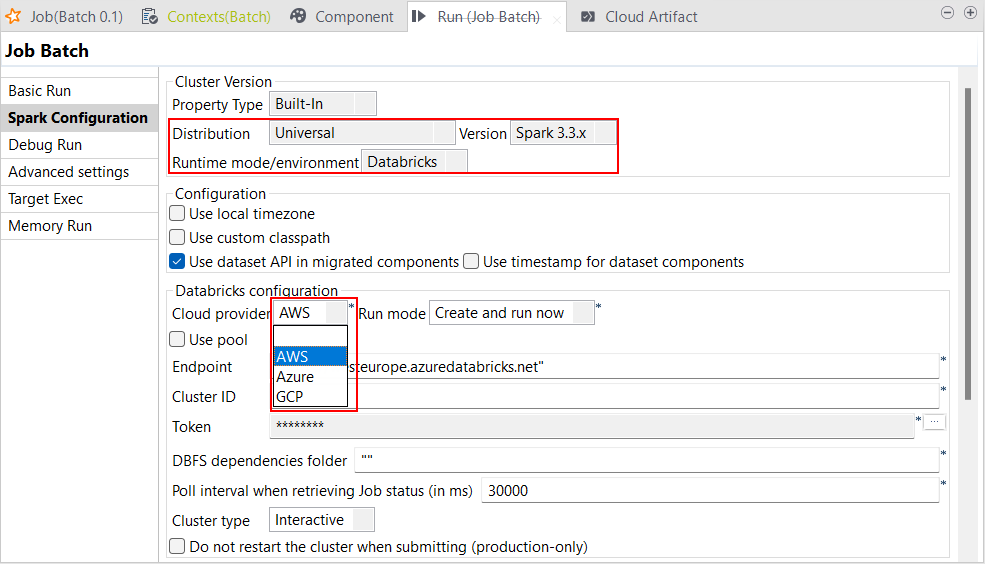
Support for Databricks runtime 11.x with Spark Universal 3.3.x |
You can now run your Spark Batch and Streaming Jobs on job and all-purpose
Databricks clusters on Google Cloud Platform (GCP), AWS, and Azure using Spark
Universal with Spark 3.3.x. You can configure it either in the Spark
Configuration view of your Spark Jobs or in the
Hadoop Cluster Connection metadata wizard. When you select this mode, Talend Studio is compatible with Databricks 11.x version. With the general
availability of this feature, the following previous known issues are now
fixed:
|
All subscription-based Talend products with Big Data |
|
Support for BigDecimal in tRedshiftOutput |
You can now use BigDecimal value in the schema of the tRedshiftOutput
component in your Spark Batch Jobs.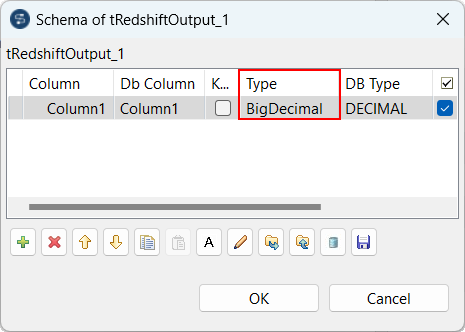
|
All subscription-based Talend products with Big Data |
|
Support for tGSConfiguration with Spark Universal |
You can now use the tGSConfiguration component to provide access to Google Storage with other input and output components. This feature applies to both Spark Batch and Spark Streaming Jobs. |
All subscription-based Talend products with Big Data |
|
Support for schema registry |
You can now use schema registry in Spark Streaming Jobs with the following
components:
Schema registry allows Talend Studio to register information about Avro records. 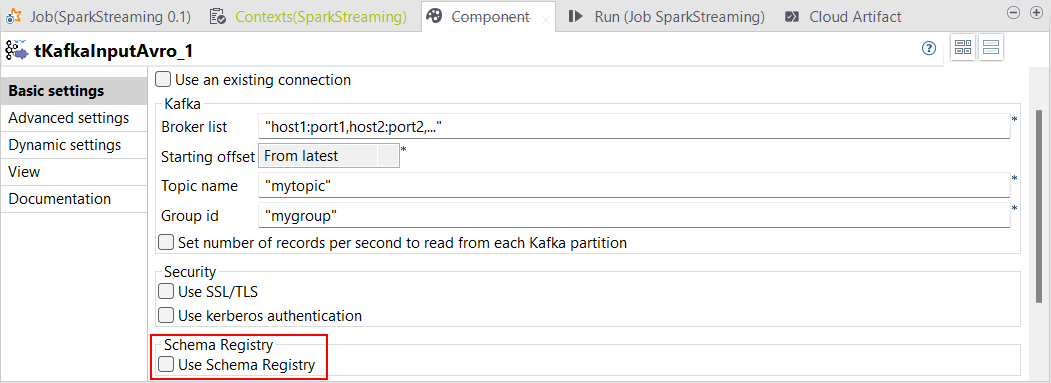
|
All subscription-based Talend products with Big Data |
|
Support for S3 Select |
You can now use S3 Select with tFileInputDelimited and tFileInputJSON when
using tS3Configuration as a storage component in your Spark Jobs running with
Spark Universal in either YARN cluster (with an Amazon EMR cluster) or
Databricks modes. S3 Select allows you to reduce the amount of data retrieved
from S3 using Spark SQL queries. When you run your Spark Jobs on Databricks, the S3 bucket must be in the same region as the cluster, otherwise you will get an S3 exception on the cluster side. |
All subscription-based Talend products with Big Data |
Did this page help you?
If you find any issues with this page or its content – a typo, a missing step, or a technical error – let us know how we can improve!