
Configuring the data transformation
The tMap component is configured to join the movie data and the director data.
Once the movie data and the director data are loaded into the Job, you need to configure the tMap component to join them to produce the output you expect.
Procedure
-
Double-click tMap to open its
Map Editor view.
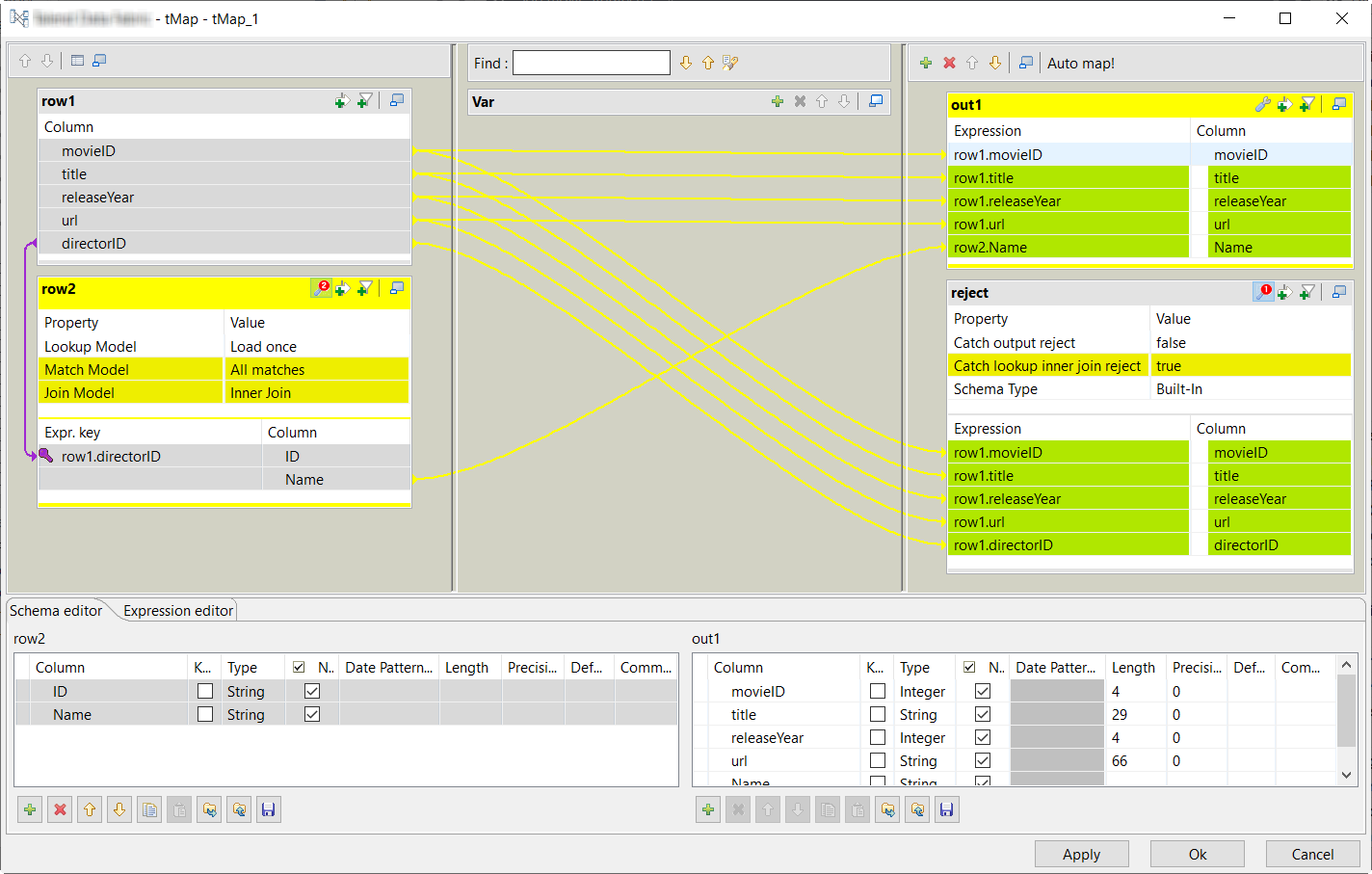
-
On the lookup flow table, click the
 button to
display the settings panel for the join operation.
button to
display the settings panel for the join operation.
-
On the reject output flow
table, click the button to open the setting panel.
Results
The transformation is now configured to complete the movie data with the names of their directors and write the movie records that do not contain any director data into a separate data flow.
Did this page help you?
If you find any issues with this page or its content – a typo, a missing step, or a technical error – let us know how we can improve!