
Converting the Job
Converting the existing Spark Batch Job to a Spark Streaming
Job.
Before you begin
-
You have launched Talend Studio and opened the Integration perspective.
-
You have created the aggregate_movie_director_spark Spark Batch Job described in Joining movie and director information using an Apache Spark Batch Job and run it successfully.
Procedure
-
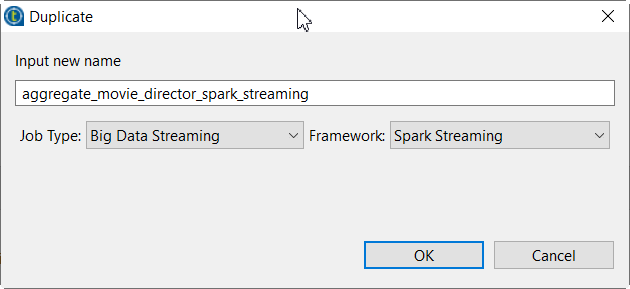
Right-click the aggregate_movie_director_spark Job and from the
contextual menu, select Duplicate.
The Duplicate window is opened.
Results
This new Spark Streaming Job is now ready for further editing.
Did this page help you?
If you find any issues with this page or its content – a typo, a missing step, or a technical error – let us know how we can improve!