Exploring semantic categories of data columns
About this task
Procedure
-
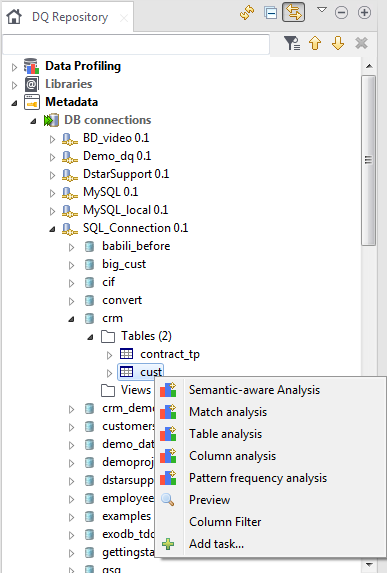
Right-click the table and select Semantic-aware
Analysis, or right-click a set of columns in the table and select
Semantic-aware Analysis.
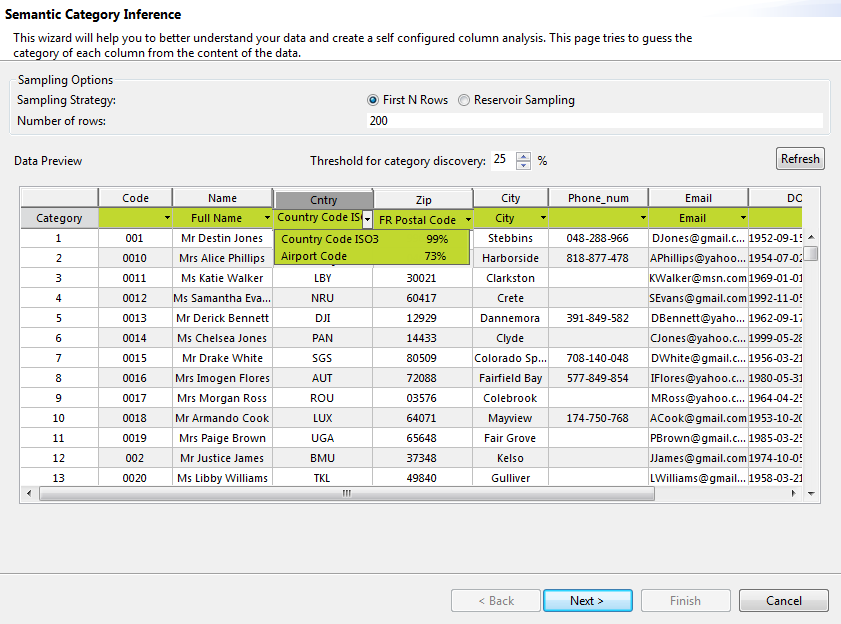
The semantic wizard opens listing all the columns of the table or listing the selected set of columns depending on whether you started the analysis on a table or on a set of columns respectively. The Category line in the wizard assigns semantic categories for the matched columns.