
Generating an analysis on the join results to analyze duplicates
In some cases, when you analyze database tables that have some duplicate records and a join clause, using an SQL business rule, the join results show that there are more rows in the joint than in the analyzed table.
You can generate a ready-to-use analysis to analyze these duplicate records. The results of this analysis help you to better understand why there are more records in the join results than in the table.
Before you begin
For more information, see Creating a table analysis with an SQL business rule with a join condition.
Procedure
-
Right-click the row count or duplicate count results in the table, or right-click
the result bar in the chart itself and select and action to perform:
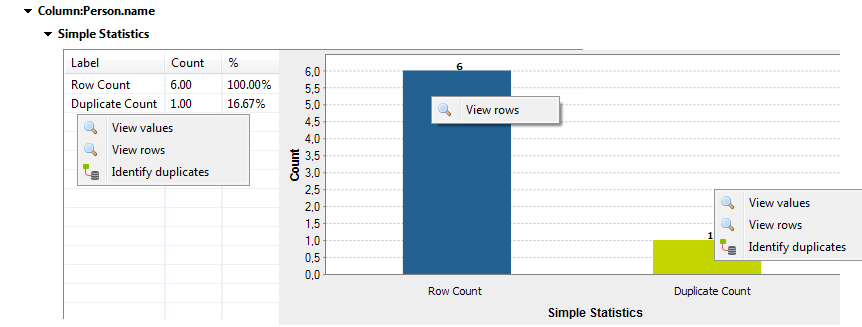
- View rows to open a view on a list of all data rows or duplicate rows in the analyzed column.
- View values to open a view on a list of the duplicate data values of the analyzed column.
- Identify duplicates to generate a ready-to-use Job that identifies and separates unique and duplicate records in the selected column for subsequent processing. This Job outputs all the duplicates in a reject CSV file by default, and writes the unique values in another separate file.