
Generating a Job to Identify duplicate values in an analyzed column
When you use the
Profiling
perspective to analyze a column in a database table and provide simple
statistics on the number of distinct, unique, and duplicate values, you can later generate
a ready-to-use Job that removes duplicate values from the specified column.
Before you begin
Procedure
-
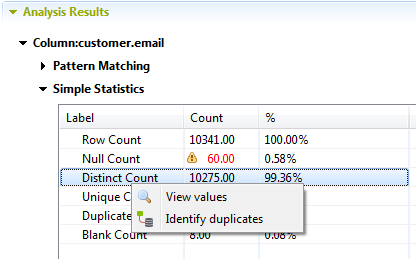
Click the name of the analyzed column in which you want to separate unique and
duplicate values, and then click Simple Statistics to
expand the simple statistics section.
-
In the Label list, right-click Distinct
Count, Unique Count or
Duplicate Count and then select Identify
duplicates from the contextual menu.
The Integration perspective opens in Talend Studio showing the generated Job with the corresponding components.
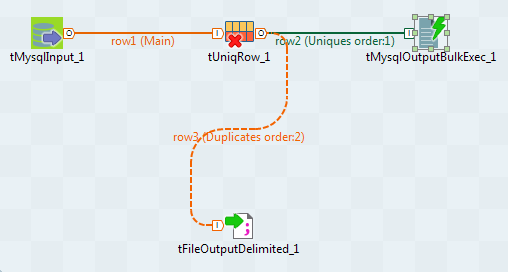
The database input component and the tUniqRow components are already configured according to your connection and the column you are analyzing.
The two output components are file components in this ready-to-use Job, but you can replace them with database output components to write the duplicate and distinct values directly in the desired database.
-
Configure the two output components:
-
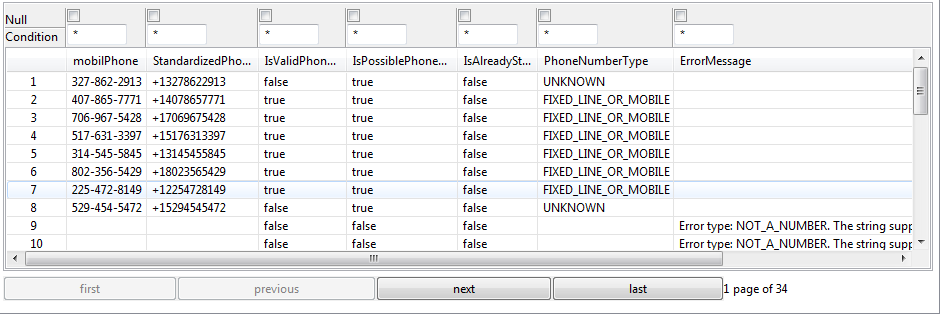
If required, right-click tFileOutputdelimited in
the generated Job and select Data Viewer.
A preview of the standardized data is open in Talend Studio.
-
If required, right-click tFileOutputdelimited in
the generated Job and select Data Viewer.