
Encoder les données d'apprentissage
Procédure
-
Reliez le tFileInputDelimited au tModelEncoder à l'aide d'un lien Main.
-
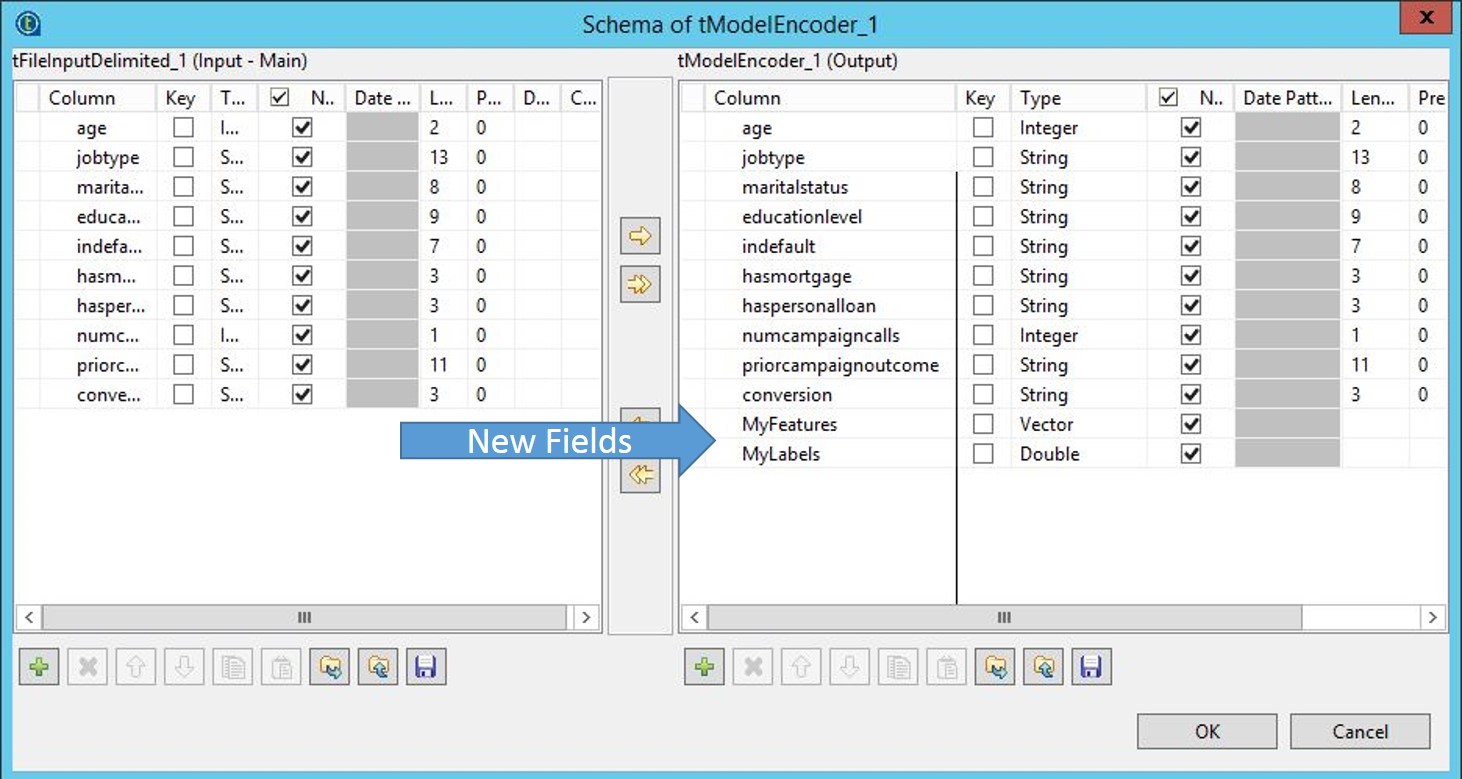
Ajoutez deux colonnes à la sortie : MyFeatures, de type Vector et MyLabels, de type Double.
-
Ajoutez le code suivant dans le champ Parameters.
featuresCol=MyFeatures;labelCol=MyLabels;formula=conversion ~ age + jobtype + maritalstatus + educationlevel + indefault + hasmortgage + haspersonalloan + numcampaigncalls + priorcampaignoutcome
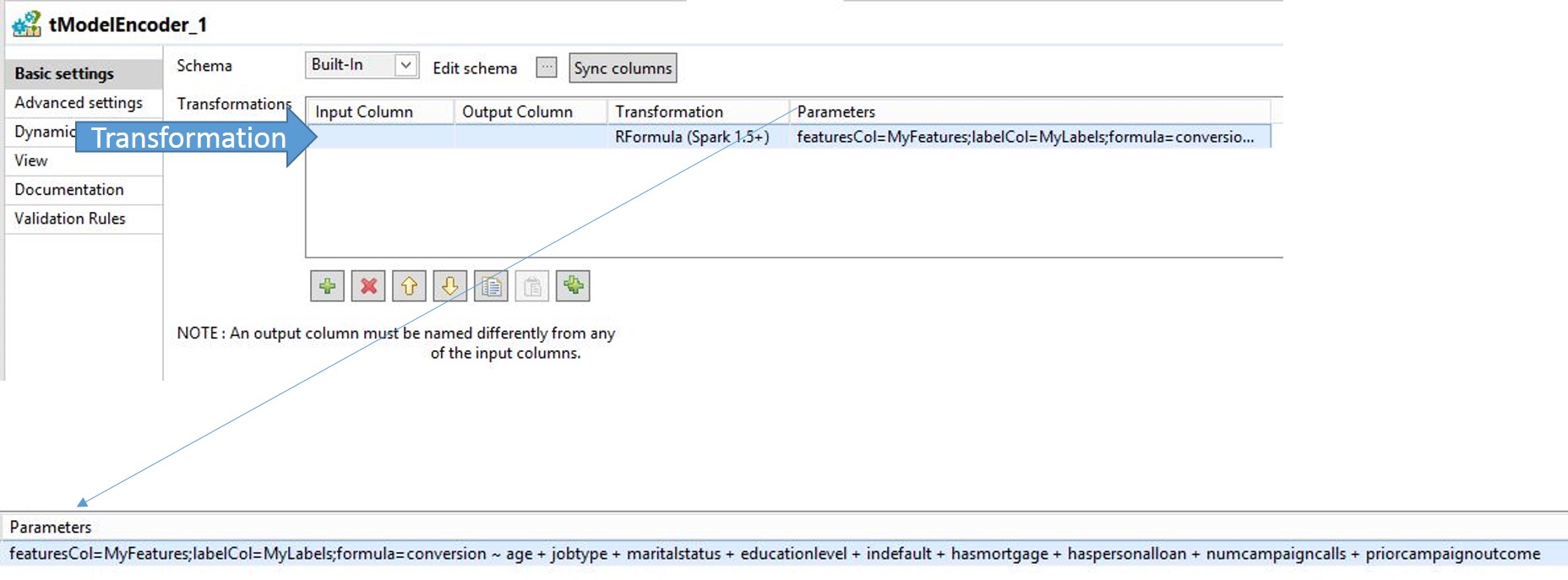
Les deux colonnes ajoutées au schéma, MyFeatures et MyLabels sont référencées ici. La formule est une syntaxe standard utilisée dans le langage de programmation R, utilisé pour le calcul de statistiques et les graphiques avancés. Pour plus d'informations, consultez The R Project (en anglais).
Dans l'échantillonnage de données, il y a neuf attributs et une cible. Dans la formule R ci-dessus, la cible à prédire est la conversion et se situe à gauche du tilde. Toutes les colonnes à droite du caractère tilde sont les attributs. Les deux composants restant, featuresCol et labelCol, sont des valeurs factices pour les tuples et les libellés des attributs.
Cette page vous a-t-elle aidé ?
Si vous rencontrez des problèmes sur cette page ou dans son contenu – une faute de frappe, une étape manquante ou une erreur technique – dites-nous comment nous améliorer !