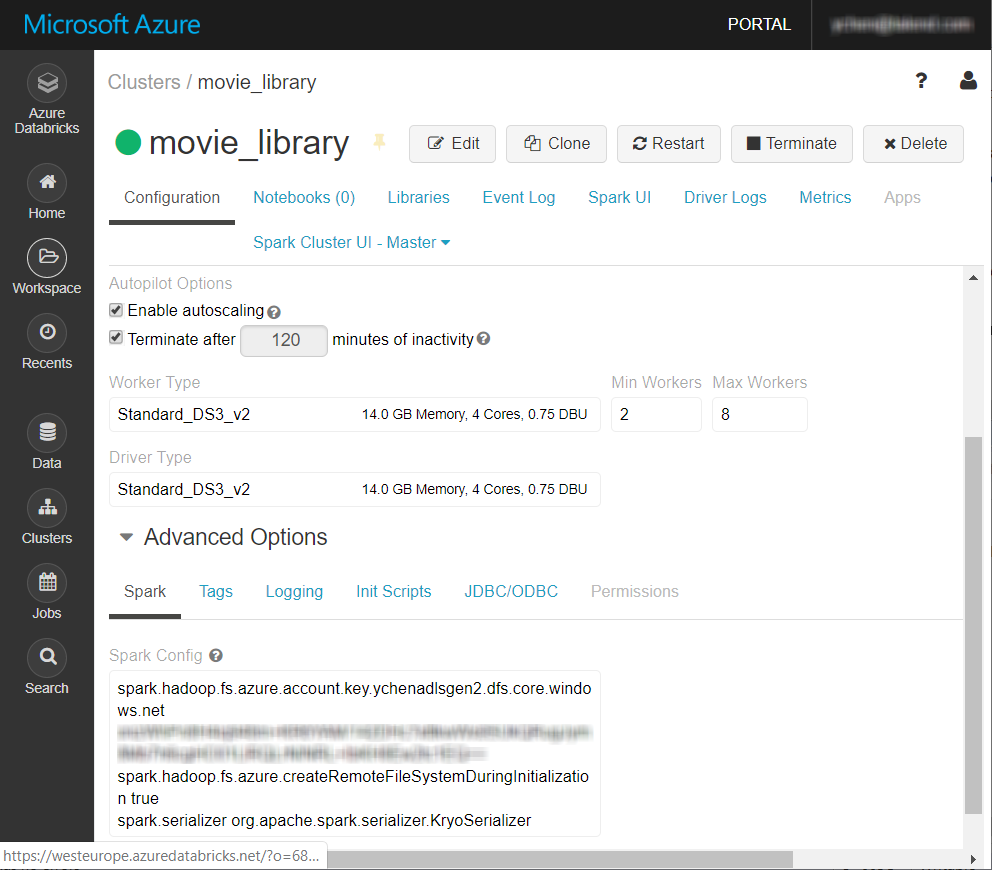
Azure StorageシステムにDatabricksからアクセスするためにAzure固有のプロパティを追加する
クラスターがAzure Storageにアクセスできるように、Azure固有のプロパティをDatabricksクラスターのSpark設定に追加します。
この操作が必要なのは、Apache SparkのTalendジョブでAzure Blob StorageまたはAzure Data Lake StorageをDatabricksと併用する場合のみです。
始める前に
-
DatabricksのSparkクラスターが正しく作成され、実行されていることと、バージョンがStudioでサポートされていることを確認します。Azure Data Lake Storage Gen 2を使う場合は、Databricks 5.4のみがサポートされています。
詳細は、Azureドキュメンテーションの「[Create Databricks workspace] (Databricksワークスペースの作成)」をご覧ください。
- Azureアカウントを持っています。
- 使用するAzure Blob StorageまたはAzure Data Lake Storageサービスが適切に作成されており、それにアクセスするための適切な権限があります。Azure Storageの詳細は、AzureドキュメントのAzure Storageチュートリアルをご覧ください。
手順
-
Databricksクラスター ページの[Configuration] (設定)タブで、ページ下部のSpark タブまでスクロールします。
例