
ジョブを実行
手順
ジョブを保存し、[F6]を押して実行します。
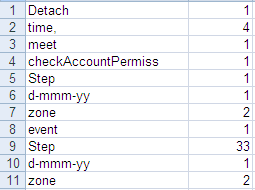
出力Excelファイルが定義したパスに書き込まれます。このファイルは、抽出された英単語の語幹を[translation] (変換)カラムに保持し、[count]カラムに各語幹の数を保管します。
以下の図は、出力ファイルの抽出を示しています。
このページは役に立ちましたか?
このページまたはコンテンツに、タイポ、ステップの省略、技術的エラーなどの問題が見つかった場合は、お知らせください。改善に役立たせていただきます。