メイン コンテンツをスキップする
補完的コンテンツへスキップ
Qlik.com
Community
Learning
日本語 (変更)
Deutsch
English
Français
日本語
中文(中国)
閉じる
ドキュメント
Qlik Talend ドキュメンテーション
リリース ノート
インストールとアップグレード
データ統合
管理と実行
データ品質とガバナンス
アプリケーションと API 統合
追加のリソース
API ドキュメンテーション ポータル
セキュリティ ポータル
Talend Archive
Qlik ヘルプ
Getting Started
Getting started with Talend cloud
Talend Cloud
Talend Cloud API Designer
Talend Cloud Data Inventory
Talend Cloud Data Preparation
Talend Cloud Data Stewardship
Talend Cloud Pipeline Designer
Talend Cloud API Services Platform
Getting started with Talend on premises
Talend Data Fabric
Talend Data Preparation
Talend Data Stewardship
日本語 (変更)
Deutsch
English
Français
日本語
中文(中国)
検索
ヘルプを検索
メニュー
閉じる
ヘルプを検索
こちらにフィードバックをお寄せください
Talend Components
Amazon Redshift
Amazon Redshiftのシナリオ
Amazon S3との間でデータをロード/アンロード
コンポーネントを設定
データをRedshiftからS3上のファイルにアンロードする
このページ上
手順
手順
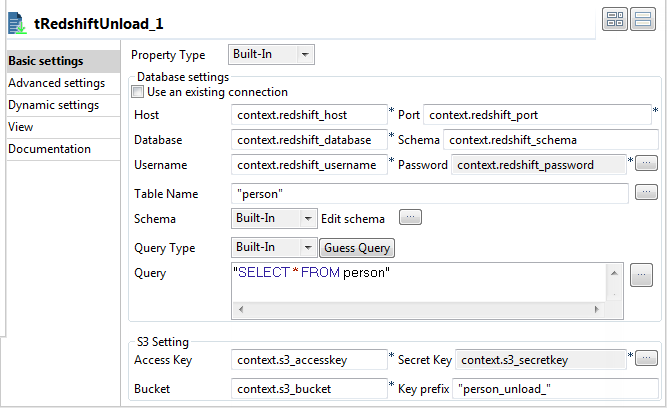
tRedshiftUnload
コンポーネントをダブルクリックし、
[Component] (コンポーネント)
タブで
[Basic settings] (基本設定)
ビューを開きます。
フィールド
[Host] (ホスト)
、
[Port] (ポート)
、
[Database] (データベース)
、
[Schema] (スキーマ)
、
[Username] (ユーザー名)
、および
[Password] (パスワード)
にそれぞれのコンテキスト変数を入力します。
フィールド
[Access Key] (アクセスキー)
、
[Secret Key] (シークレットキー)
、および
[Bucket] (バケット)
にも、それぞれ対応するコンテキスト変数を入力します。
[Table Name] (テーブル名)
フィールドに、データが書き込まれるテーブルの名前を入力します。この例では、
person
です。
[Edit schema] (スキーマを編集)
の横にある
[...]
ボタンをクリックし、ポップアップウィンドウで、整数タイプの
ID
と文字列タイプの
Name
という2つのカラムを追加して、スキーマを定義します。
[Query] (クエリー)
フィールドに、結果をアンロードする時のベースとなる次のSQLステートメントを入力します。
"SELECT * FROM person"
[Key prefix] (キープレフィックス)
フィールドにアンロードファイルのプレフィックス名を入力します。この例では、
person_unload_
です。
このページは役に立ちましたか?
このページまたはコンテンツにタイポ、ステップの省略、技術的エラーなどの問題が見つかった場合はお知らせください。
こちらにフィードバックをお寄せください
前のトピック
Redshiftのテーブルからデータを取得する
次のトピック
アンロードされたファイルをAmazon S3に取得する