
2つの解析レベルを使って非ストラクチャー化データから情報を抽出する
このシナリオはTalend Data Management Platform、Talend Big Data PlatformTalend Real-Time Big Data Platform、Talend MDM PlatformTalend Data Services Platform、Talend MDM PlatformおよびTalend Data Fabricにのみ適用されます。
Talendでサポートされているテクノロジーの詳細は、Talendコンポーネントをご覧ください。
このシナリオでは、非ストラクチャー化データから一部の情報を抽出するルールセットを構築する方法について説明します。基本的なANTLRルールを使ってデータをトークン化する方法と、詳細なルールを使ってANTLRによって作成された各トークンを正規表現と照合する方法について説明します。
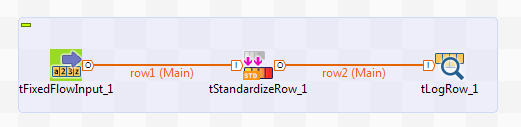
このシナリオで使うコンポーネントは、以下のとおりです。
-
非ストラクチャー化データ文字列を作成するtFixedFlowInputコンポーネント。
-
データ文字列から液体の量を抽出するために必要なルールを定義するtStandardizeRowコンポーネント。
-
出力データを表示するtLogRowコンポーネント。
このページは役に立ちましたか?
このページまたはコンテンツに、タイポ、ステップの省略、技術的エラーなどの問題が見つかった場合は、お知らせください。改善に役立たせていただきます。