
Utilisation de deux niveaux de parsing pour extraire des informations de données non structurées
Ce scénario s'applique uniquement à Talend Data Management Platform, Talend Big Data Platform, Talend Real-Time Big Data Platform, Talend MDM Platform, Talend Data Services Platform, Talend MDM Platform et Talend Data Fabric.
Pour plus de technologies supportées par Talend, consultez Composants Talend.
Ce scénario décrit comment construire un ensemble de règles pour extraire des informations de données non structurées. Il explique comment utiliser une règle ANTLR simple afin de diviser en jetons les données, puis d'utiliser une règle avancée afin de vérifier chaque jeton créé par ANTLR par rapport à une expression régulière.
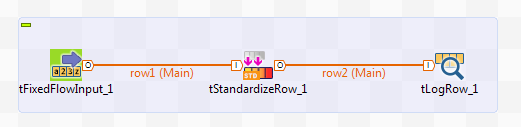
Ce scénario utilise :
-
un composant tFixedFlowInput pour créer les chaînes de données non structurées,
-
un tStandardizeRow afin de définir les règles nécessaires à l'extraction des quantités de liquide des chaînes de données,
-
un tLogRow pour afficher les données de sortie.
Cette page vous a-t-elle aidé ?
Si vous rencontrez des problèmes sur cette page ou dans son contenu – une faute de frappe, une étape manquante ou une erreur technique – dites-nous comment nous améliorer !