
別のデータセットのデータを動的に使用
ルックアップ機能は現在のプレパレーションからのデータを参照データセット内のデータとマッチングするので、ユーザーはこの参照データをプレパレーションに追加できます。
情報メモヒント: Talendでは、最大100,000行、10カラムのデータセットでルックアップ機能を使用することをお勧めしています。
Talend Cloud Data Preparationでルックアップ機能を使用している場合、これまでTalend Cloud Data Inventory経由でルックアップデータセットに追加されていたカラムの説明はプレパレーションで表示されるようになります。 この例では、顧客が住んでいるアメリカの州に関する情報を含むプレパレーションを用いて作業するという想定ですが、州を2文字のコードだけで識別する設定になっています。これと並行して2番目のデータセットがあり、そこでは2文字の米州コードが州のフルネームとマッチングされています。ユーザーはルックアップ機能を使ってこの情報を取得し、プレパレーションに追加できます。 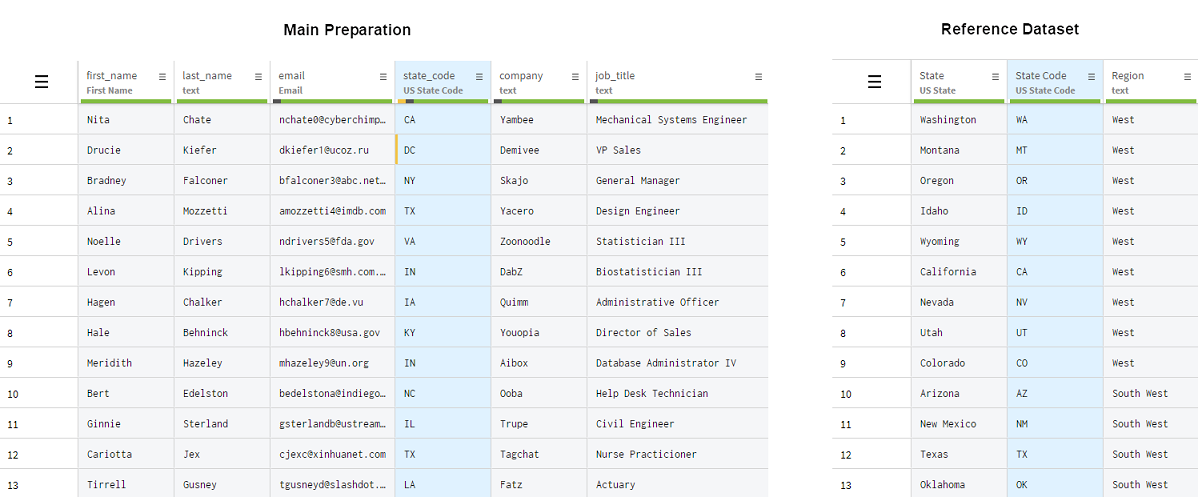
始める前に
- Google Cloud Storage (クラウドファイルシステム)
- Azure Synapse (データベース)
- Google BigQuery (データベース)
- Google BigTable (データベース)
- Marketo (ビジネスアプリ)
- Google Analytics (ビジネスアプリ)
- NetSuite (ビジネスアプリ)
- Workday (ビジネスアプリ)
- Kafka (メッセージング)
- RabbitMQ (メッセージング)
手順
-
ルックアップボタンをクリックし、ルックアップパネルを開きます。
-
[Select dataset] (データセットを選択)をクリックし、既存のデータセットを選択します。
-
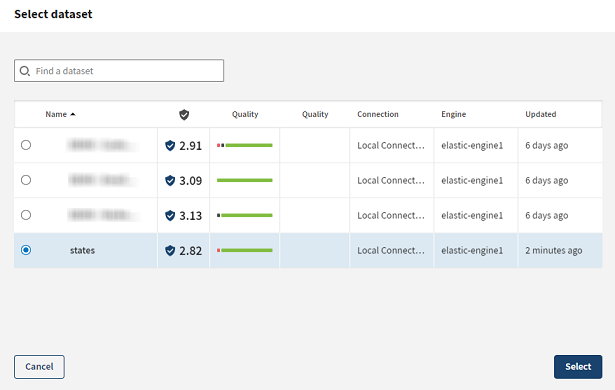
ルックアップの実行に使いたいデータセットを選択します。
この場合は、2文字の州コードとそれに一致する名前のリストを含むデータセットを追加する必要があります。データセットはあらかじめTalend Cloud Data Preparationにインポートされています。
-
[Current preparation] (現在のプレパレーション)と[Lookup dataset] (ルックアップデータセット)ドロップダウンリストから、メインのプレパレーションとルックアップデータセットで一致するカラム(この例ではstate_codeとStates Code)を選択します。
ルックアップを実行するには、ブレンドするプレパレーションとデータセット内に一致データを持つカラムが少なくとも1つ存在している必要があります。

-
[Columns to add] (追加するカラム)ドロップダウンリストから、週が含まれているカラムを選択し、現在のデータセット(この例ではState)に追加します。
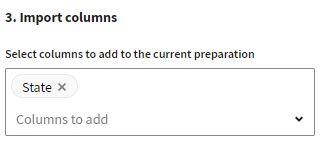
-
[Submit] (送信)をクリックします。メインのプレパレーションと参照データセットの間で一致する各州コードの州名が取得されました。
ルックアップ機能は以下のように動作します。
- メインのプレパレーションと参照データセットの両方に共通の値があれば、追加情報が取得されます。
- プレパレーションには存在し、参照データセットには存在しないという値があれば、ルックアップ操作は結果カラムに空のセルを残します。
- 参照データセットからの値に一致するものがメインのプレパレーションに見つからない場合、追加情報は取得されません。
Talend Cloud Data Preparationのルックアップ操作の背後にあるロジックは、Vennダイアグラムで言う左外部結合に対応します。
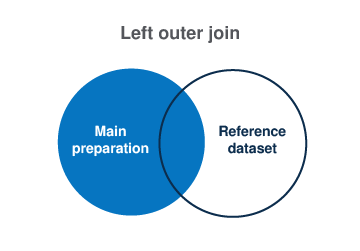
ここでの例に当てはめると、州コードに関する共通情報を使用して結合を作成し、2番目のデータセットから有用な情報のみを取得して、1番目のデータセットをエンリッチ化したということになります。
タスクの結果
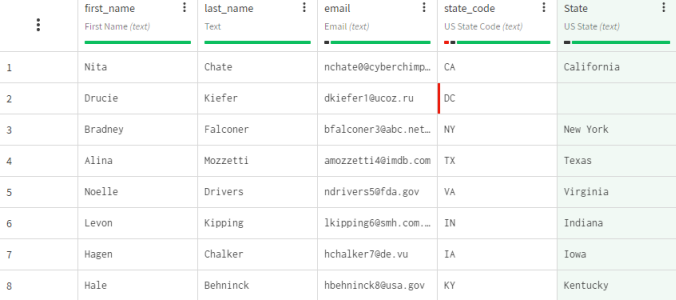
前述の例で説明されなかったルックアップ機能のもう1つの動作は、参照データセットからの値に重複や空があった場合の処理です。
次の例をご覧ください。州コードの1つがプレパレーションにありません。また、参照データセットに[NY]州コードの重複エントリーがあります。この例でNYは2つの値を取る可能性があります。New YorkとNueva Yorkです。ただし、どちらのエントリーも同じである可能性も十分にあります。
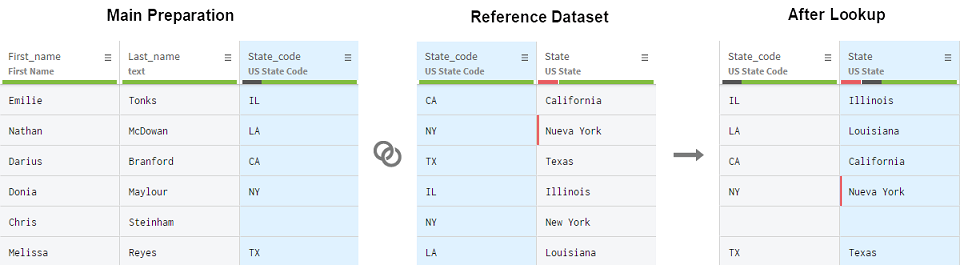
上記の結果は、以下の動作を適用して得られたものです。
- 参照データセット内に同じ値が複数存在する場合、初回の出現のみがマッチングされます。この例では[Nueva York]です。
- プレパレーション内の空のセルは、空のセルとマッチングされます。
このページは役に立ちましたか?
このページまたはコンテンツに、タイポ、ステップの省略、技術的エラーなどの問題が見つかった場合は、お知らせください。改善に役立たせていただきます。