
一致分析の設定
手順
-
[Limit] (制限)フィールドで、データサンプルとして使用したいデータレコードの数を設定します。
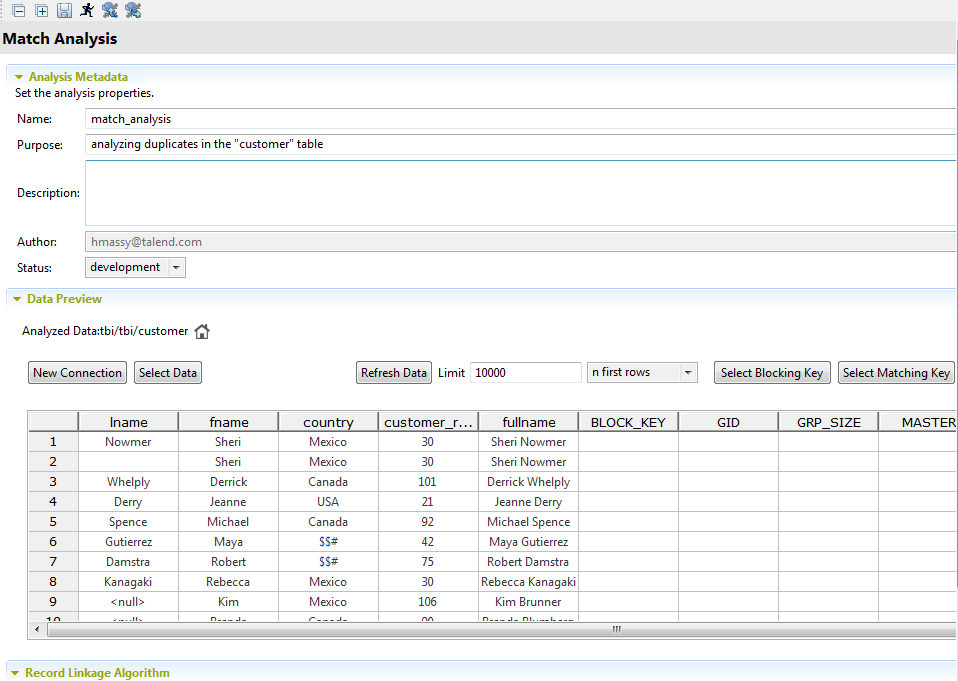
-
一致分析エディターで以下を選択します。
オプション
内容...

選択されたテーブルを、ツリービューの[Metadata] (メタデータ)ノードの下に配置します。
[New Connection] (新規接続)
一致分析エディター内からデータベースやファイルへの接続を作成します。作成した接続をこのエディターで展開し、一致させるカラムを選択できます。
データソースへの接続を作成する方法は、データソースへの接続を作成 (英語のみ)をご覧ください。
[Select Data] (データを選択)
テーブルにリスト表示されているカラムの選択をアップデートします。
分析用のデータセットを変更すると、サンプルデータの一致結果に表示されるチャートは自動的にクリアされます。定義した新しいデータの一致結果を計算する場合は、[Chart] (チャート)をクリックする必要があります。
[Refresh Data] (データを更新)
テーブルにリスト表示されているカラムのビューを更新します。 [n first rows] (最初のn行)
または
[n random rows] (ランダムなn行)
選択したカラムから最初のNデータレコードをテーブルにリスト、または選択したカラムからランダムなNレコードをリスト表示します。 ブロッキングキーを選択
ブロックで処理されたデータのパーティショニング先に基づいて、入力フローからカラムを定義します。
詳細は、マッチングルールを定義 (英語のみ)をご覧ください。
[Select Matching Key] (マッチングキーを選択)
一致アルゴリズムを適用する入力フローから、マッチングルールとカラムを定義します。
詳細は、マッチングルールを定義 (英語のみ)をご覧ください。
[Store on disk] (ディスクに保存)
システムパフォーマンスを最大化できるよう、処理されたデータブロックをディスクに保管します。
[Max buffer size] (最大バッファーサイズ): 処理されたデータに割り当てる物理メモリのサイズを入力します。
[Temporary data directory path] (一時データのディレクトリーパス): 一時ファイルを保管するディレクトリーへのパスを設定します。
タスクの結果
[Data Preview] (データプレビュー)テーブルには、一致データの結果を表示するカラムが追加されます。これらのカラムの意味は次のとおりです。
|
カラム |
説明 |
|
GID |
グループ識別子を表します。 |
|
GRP_SIZE |
グループ内のレコード数をカウントします。マスターレコードでのみ計算されます。 |
|
MASTER |
マッチング比較で使用されるレコードがマスターレコードかどうか、trueまたはfalseで識別します。マスターレコードは各グループに1つのみです。 入力レコードはそれぞれマスターレコードと比較され、一致した入力レコードはグループに含められます。 |
|
SCORE |
使用される一致アルゴリズムに基づいて、入力レコードとマスターレコード間の距離を測定します。 |
|
GRP_QUALITY |
グループの最小値である品質スコアを持っているのはマスターレコードのみです。 |
|
ATTRIBUTE_SCORE |
一致するスコアと適用されたルールでキー属性として使用されるカラムの名前がリスト表示されます。 |
このページは役に立ちましたか?
このページまたはコンテンツに、タイポ、ステップの省略、技術的エラーなどの問題が見つかった場合は、お知らせください。改善に役立たせていただきます。