
HDFSファイルをプロファイリング
Talend StudioのProfilingパースペクティブから、Hive接続経由でHDFSファイルに対してシンプル統計インジケーターを使用してカラム分析を作成できます。
HDFSファイルにプロファイリング分析を作成するステップは以下のとおりです。
- Hadoopクラスターへの接続を作成します。
- Hiveサーバーへの接続を作成します。
HDFSファイルへの接続を作成する際、Hiveへの接続を同時に作成するよう画面上で指示されるため、このステップは必須ではありません。
-
HDFSファイルへの接続を作成します。
このステップに従ってHiveの 外部テーブルを作成できます。その結果、データはファイル内に残りますが、Hiveメタストア内にテーブルの定義が作成されます。これにより、Talend StudioはHive接続経由でファイル内のデータにSQLクエリーを実行できるようになります。
- Hiveテーブルの単純なインジケーターでカラム分析を作成します。
続いて、必要に応じて分析の設定を変更し、他のインジケーターを追加できます。後で、同じHiveテーブルを使用して、このHDFSファイルに別の分析を作成することもできます。
- TXT
- CSV
- Parquet (フラットストラクチャーの場合)
Hadoopクラスターへの接続の作成
Before you begin
- Profilingパースペクティブを選択済みであること。
- HadoopディストリビューションとそのHDFSへの適切なアクセス権があること。
Procedure
-
[DQ Repository] (DQリポジトリー)ツリービューで[Metadata] (メタデータ)を展開し、[Hadoop Cluster] (Hadoopクラスター)を右クリックし、[Create Hadoop Cluster] (Hadoopクラスターの作成)を選択します。
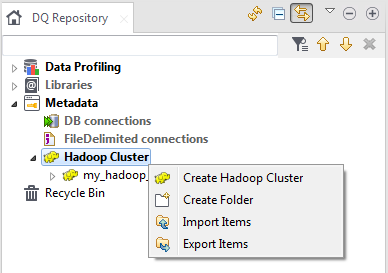 ウィザードが表示され、クラスターへの接続を作成するステップが段階的に説明されます。
ウィザードが表示され、クラスターへの接続を作成するステップが段階的に説明されます。
Results
Hiveへの接続の作成
Before you begin
Hadoopディストリビューションへの接続が作成済みであること。
Procedure
-
[DQ Repository] (DQリポジトリー)ツリービューで、使用するHadoop接続を右クリックし、[Create Hive] (Hiveの作成)を選択してウィザードを開きます。
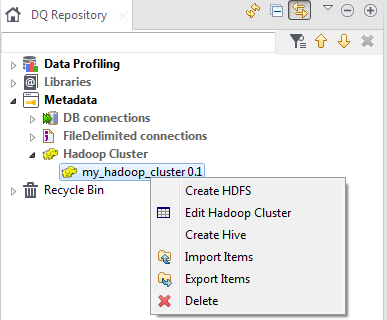
Results
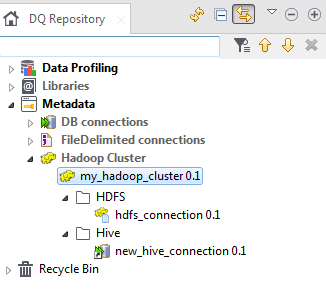
Hive接続の作成については、Hiveメタデータを一元管理をご覧ください。
HDFSファイルへの接続の作成
Before you begin
- Profilingパースペクティブを選択済みであること。
- Hadoopディストリビューションへの接続が作成済みであること。
Procedure
Results
HDFS接続の作成については、HDFSメタデータを一元管理をご覧ください。
Hiveテーブルを使用してHDFSファイルへのプロファイリング分析を作成する方法
Before you begin
- Profilingパースペクティブを選択済みであること。
- HadoopディストリビューションおよびHDFSファイルへの接続が作成済みであること。
About this task
- TXT
- CSV
- Parquet (フラットストラクチャーの場合)
Procedure
-
[DQ Repository] (DQリポジトリー)ツリービューで、使用するHDFS接続を右クリックし、[Create Simple Analysis] (単純分析の作成)を選択します。
ダイアログボックスが開き、接続のHDFSスキーマがリスト表示されます。
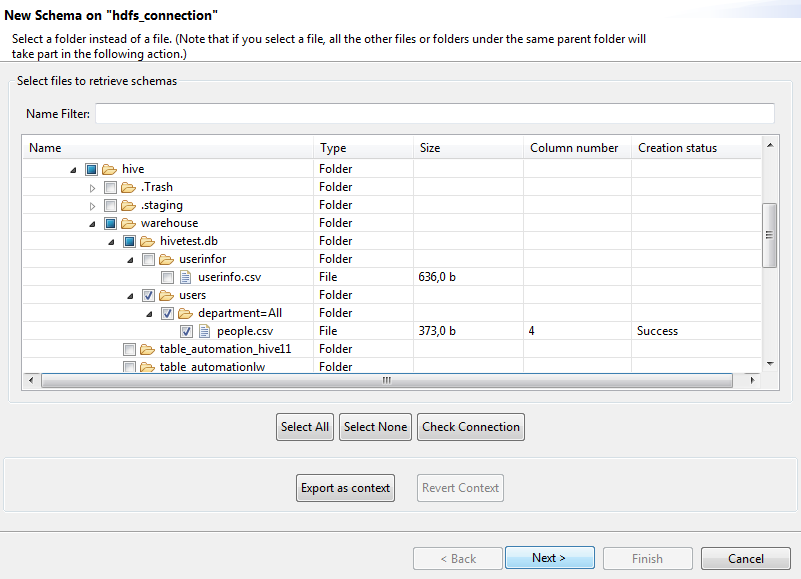
-
[Check Connection] (接続をチェック)をクリックして接続ステータスを確認し、[Next] (次へ)をクリックして次のステップに進みます。選択したファイルのスキーマがリスト表示されます。
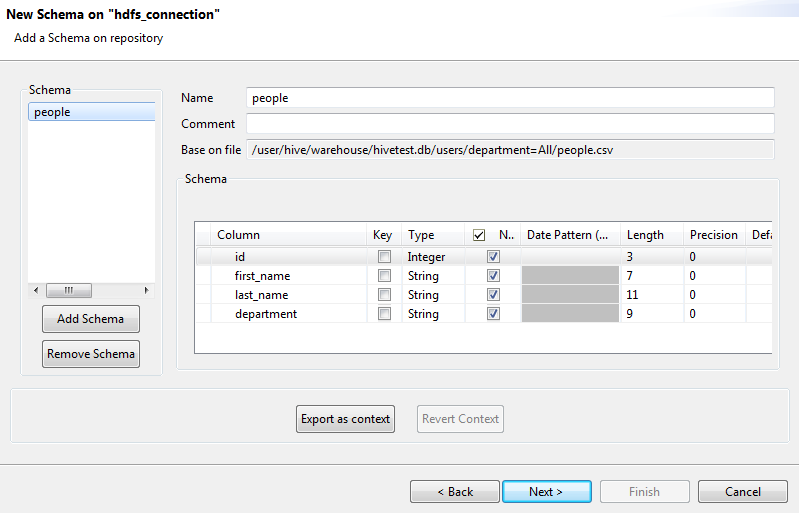
- Optional:
必要に応じて、テーブルに新しい名前を入力します。テーブル名には小文字を使用してください。Hiveはテーブルを小文字で保存します。
![[新しいテーブル名]フィールドにある小文字の名前の例。](/ja-JP/studio-user-guide/8.0-R2024-08/Content/Resources/images/profile_hdfs6.png)
-
分析メタデータを設定し、[Finish] (終了)をクリックします。
![[データプレビュー]セクションと[分析済みカラム]セクションの概要。](/ja-JP/studio-user-guide/8.0-R2024-08/Content/Resources/images/profile_hdfs9.png)
選択したHDFSファイルの新しい分析が自動的に作成され、分析エディター内に開きます。シンプル統計インジケーターがカラムに自動的に割り当てられます。
分析は実際にHiveテーブルに適用されますが、外部テーブルメカニズムを使用してHDFSからのデータに基づいて統計を計算します。外部テーブルは、Hive外の元のファイルにデータを保持します。分析のために選択したHDFSファイルは削除され、以後は分析を実行できません。
-
分析を実行し、エディターの[Analysis Results] (分析結果)セクションに結果を表示させます。
![[シンプル統計]インジケーター用のテーブルとグラフィック。](/ja-JP/studio-user-guide/8.0-R2024-08/Content/Resources/images/profile_hdfs10.png)
カラム分析の詳細は、カラム分析をご覧ください。