
Big Data
|
Funktion |
Beschreibung |
Verfügbar in |
|---|---|---|
| Unterstützung für Amazon EMR ab 6.6.0 und 6.7.0 mit Spark Universal 3.2.x |
Sie können Ihre Spark-Jobs jetzt in einem Amazon EMR-Cluster unter Rückgriff auf Spark Universal mit Spark 3.2.x im Yarn-Cluster-Modus ausführen. Die Konfiguration erfolgt entweder in der Ansicht Spark Configuration (Spark-Konfiguration) Ihrer Spark-Jobs oder im Metadaten-Assistenten Hadoop Cluster Connection (Hadoop-Clusterverbindung). Wenn Sie diesen Modus auswählen, ist Talend Studio mit den Versionen 6.6.0 und 6.7.0 von Amazon EMR kompatibel. |
Alle abonnementbasierte Produkte von Talend mit Big Data |
|
Unterstützung für Databricks Runtime 11.x mit Spark Universal 3.3.x |
Sie können Ihre Spark Batch- und Streaming-Jobs jetzt in jobbasierten wie auch in multifunktionalen Databricks-Clustern in Google Cloud Platform (GCP), AWS und Azure unter Rückgriff auf Spark Universal mit Spark 3.3.x ausführen. Die Konfiguration erfolgt entweder in der Ansicht Spark Configuration (Spark-Konfiguration) Ihrer Spark-Jobs oder im Metadaten-Assistenten Hadoop Cluster Connection (Hadoop-Clusterverbindung). Wenn Sie diesen Modus auswählen, ist Talend Studio mit Databricks 11.x kompatibel. Mit der generellen Verfügbarkeit dieser Funktion wurden die folgenden bekannten Fehler behoben:
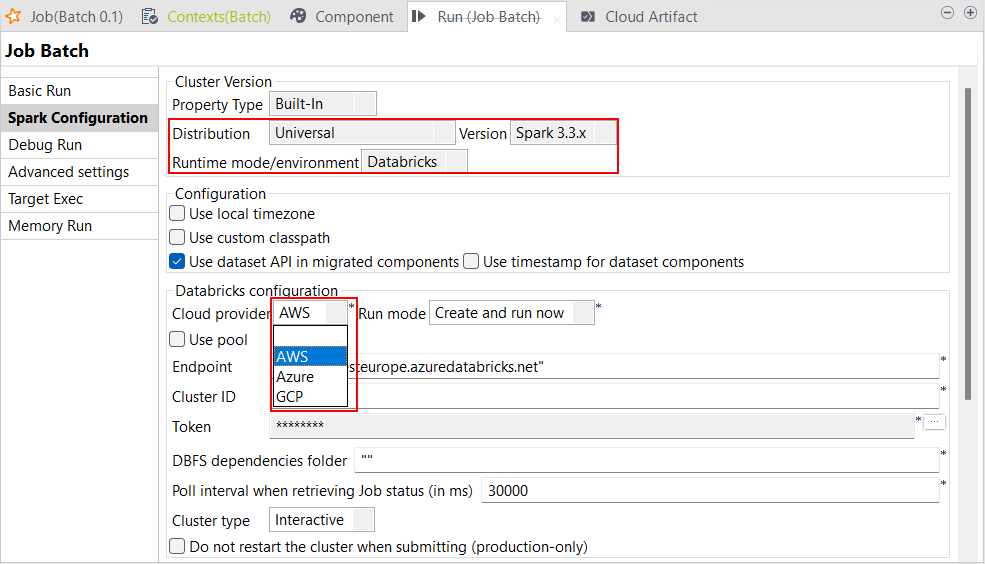
|
Alle abonnementbasierte Produkte von Talend mit Big Data |
|
Unterstützung von BigDecimal in tRedshiftOutput |
Sie können jetzt BigDecimal-Werte im Schema der tRedshiftOutput-Komponente in Ihren Spark Batch-Jobs verwenden.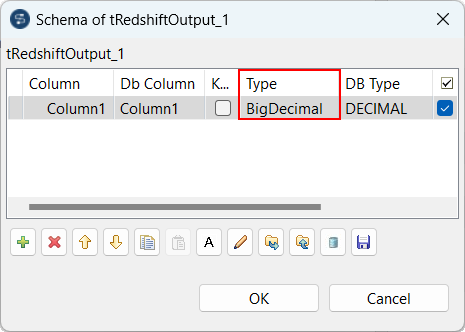
|
Alle abonnementbasierte Produkte von Talend mit Big Data |
|
Unterstützung für tGSConfiguration mit Spark Universal |
Sie können jetzt die Komponente tGSConfiguration verwenden, um einen Zugriff auf Google Storage mit anderen Eingabe- und Ausgabekomponenten bereitzustellen. Diese Funktion gilt sowohl für Spark Batch- als auch für Spark Streaming-Jobs. |
Alle abonnementbasierte Produkte von Talend mit Big Data |
|
Unterstützung der Schema-Registry |
Sie können in Ihren Spark-Jobs jetzt die Schema-Registry mit den folgenden Komponenten verwenden:
Die Schema-Registry ermöglicht Talend Studio die Registrierung von Informationen zu Avro-Datensätzen. 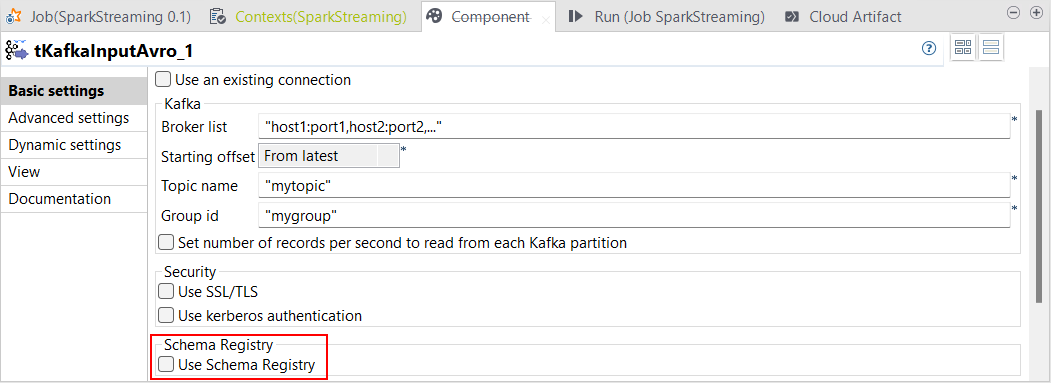
|
Alle abonnementbasierte Produkte von Talend mit Big Data |
|
Unterstützung für S3 Select |
Sie können jetzt S3 Select mit tFileInputDelimited und tFileInputJSON verwenden, wenn Sie tS3Configuration als Speicherkomponente in Spark-Jobs einsetzen, die mit Spark Universal im YARN-Cluster- (mit einem Amazon EMR-Cluster) oder Databricks-Modus ausgeführt werden. Mit S3 Select können Sie das über Spark SQL-Abfragen abgerufene Datenvolumen reduzieren. Bei der Ausführung von Spark-Jobs in Databricks muss sich das S3-Bucket im selben Bereich befinden wie das Cluster. Andernfalls wird auf Cluster-Seite eine S3-Ausnahme ausgegeben. |
Alle abonnementbasierte Produkte von Talend mit Big Data |
Hat diese Seite Ihnen geholfen?
Wenn Sie Probleme mit dieser Seite oder ihren Inhalten feststellen – einen Tippfehler, einen fehlenden Schritt oder einen technischen Fehler –, teilen Sie uns bitte mit, wie wir uns verbessern können!