
Verarbeiten von Leads in Amazon S3 und Laden der Leads in MySQL
Dieses Szenario soll Sie bei der Einrichtung und Verwendung von Konnektoren in einer Pipeline unterstützen. Es wird empfohlen, dass Sie das Szenario an Ihre Umgebung und Ihren Anwendungsfall anpassen.

Vorbereitungen
- Wenn Sie dieses Szenario reproduzieren möchten, laden Sie folgende Datei herunter und extrahieren Sie sie: s3_mysql-lead_campaign.zip.
Prozedur
-
Klicken Sie auf Autodetect (Autom. erkennen) oder geben Sie die erforderlichen Eigenschaften für den Zugriff auf die Datei in Ihrem S3-Bucket manuell ein (CSV-Format, Leerzeichen als Feldbegrenzer, keine Überschrift) und klicken Sie dann auf View sample (Sample anzeigen), um eine Vorschau Ihres Datensatz-Samples anzuzeigen.
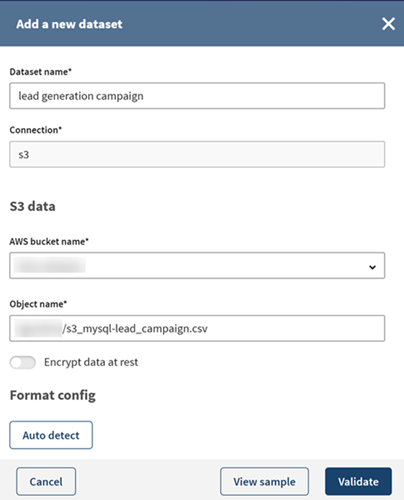
-
Klicken Sie auf
 und fügen Sie einen Prozessor vom Typ Field selector (Feldauswahl) zur Pipeline hinzu, um bestimmte Felder auszuwählen, und geben Sie einen aussagekräftigen Namen für sie ein. Daraufhin wird das Konfigurationsfenster geöffnet.
und fügen Sie einen Prozessor vom Typ Field selector (Feldauswahl) zur Pipeline hinzu, um bestimmte Felder auszuwählen, und geben Sie einen aussagekräftigen Namen für sie ein. Daraufhin wird das Konfigurationsfenster geöffnet.
-
Klicken Sie in der Ansicht Simple (Einfach) der Registerkarte Configuration (Konfiguration) auf das Symbol
 , um das Fenster Select fields (Felder auswählen) zu öffnen:
, um das Fenster Select fields (Felder auswählen) zu öffnen:
-
Wählen Sie .field2 (Feld 2) aus und klicken Sie auf das Symbol
 , um das Element in country (Land) umzubenennen, da die Felder anhand der Länder der Kunden ausgewählt werden sollen.
, um das Element in country (Land) umzubenennen, da die Felder anhand der Länder der Kunden ausgewählt werden sollen.
-
Wählen Sie .field2 (Feld 7) aus und klicken Sie auf das Symbol , um das Element in revenue (Einkommen) umzubenennen, da die Felder anhand des Einkommens der Kunden ausgewählt werden sollen.
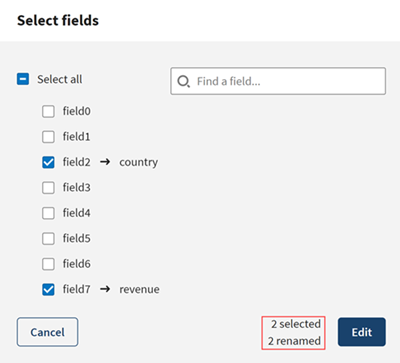
-
Wählen Sie .field2 (Feld 2) aus und klicken Sie auf das Symbol
-
Klicken Sie auf und fügen Sie einen Filter-Prozessor zur Pipeline hinzu, um die Datensätze zu filtern und ausschließlich die Kunden beizubehalten, die im Rahmen der Marketing-Kampagne ihr Einkommen bereitgestellt haben. Daraufhin wird das Konfigurationsfenster geöffnet.
-
Klicken Sie auf und fügen Sie einen Prozessor vom Typ Type Converter (Typkonverter) zur Pipeline hinzu, um das Format der Einkommensfelder (Zeichenfolgenformat) zu konvertieren. Daraufhin wird das Konfigurationsfenster geöffnet.
-
Klicken Sie auf und fügen Sie einen Prozessor vom Typ Aggregate (Aggregieren) zur Pipeline hinzu. Daraufhin wird das Konfigurationsfenster geöffnet.
-
(Optional) Klicken Sie auf den Aggregationsprozessor (Aggregate), um eine Vorschau der nach der Aggregationsoperation berechneten Daten anzuzeigen: Das durchschnittliche Einkommen pro Land.
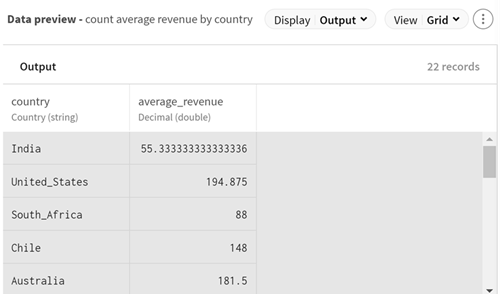
Ergebnisse
Ihre Pipeline wird ausgeführt, die in S3 gespeicherten Lead-Informationen werden bereinigt, das Einkommen wird pro Land aggregiert und der Ausgabe-Flow an die von Ihnen definierte MySQL-Zieltabelle gesendet.
Hat diese Seite Ihnen geholfen?
Wenn Sie Probleme mit dieser Seite oder ihren Inhalten feststellen – einen Tippfehler, einen fehlenden Schritt oder einen technischen Fehler –, teilen Sie uns bitte mit, wie wir uns verbessern können!