
Filtern der Kundendaten nach gültigen und ungültigen semantischen Typen
Vorbereitungen
-
Sie haben zuvor eine Verbindung zu dem System erstellt, in dem die Quelldaten gespeichert sind.
In diesem Beispiel eine Testverbindung.
-
Sie haben zuvor den Datensatz hinzugefügt, der die Quelldaten enthält.
Laden Sie folgende Datei herunter und extrahieren Sie sie: semantic_filter-customers.zip. Sie enthält eine Liste der Kunden mit Rohdaten (im Anhang dieses Dokuments bereitgestellt).
-
Sie haben außerdem die Verbindung und den zugehörigen Datensatz erstellt, der die verarbeiteten Daten aufnehmen soll.
Die Dateien werden ebenfalls in zwei Test-Datensätzen gespeichert.
Prozedur
-
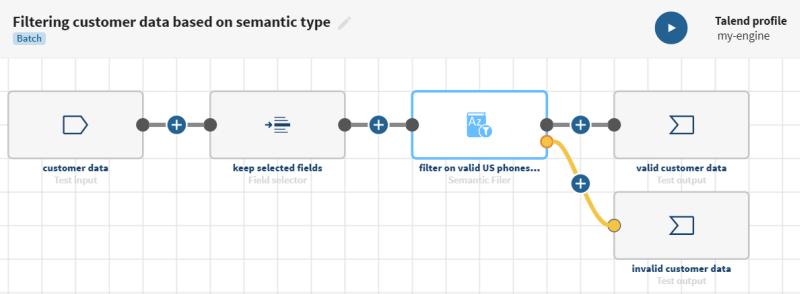
Klicken Sie auf ADD SOURCE (QUELLE HINZUFÜGEN), um ein Fenster zu öffnen, in dem Sie Ihre Quelldaten auswählen können, in diesem Fall eine Kundenliste mit Rohdaten (inkonsistente Feldnamen, leere Felder usw.) und im Vorfeld ermittelte semantische Typen.
Example
-
Klicken Sie auf
 und fügen Sie einen Prozessor vom Typ Field selector (Feldauswahl) zur Pipeline hinzu. Daraufhin wird das Konfigurationsfenster geöffnet.
und fügen Sie einen Prozessor vom Typ Field selector (Feldauswahl) zur Pipeline hinzu. Daraufhin wird das Konfigurationsfenster geöffnet.
-
Führen Sie auf der Registerkarte Configuration (Konfiguration) Folgendes durch:
-
Klicken Sie auf das Symbol
 im Auswahlmodus Simple (Einfach), um die Baumstrukturansicht zu öffnen, in der Sie die Felder auswählen und umbenennen können, die Sie beibehalten möchten.
im Auswahlmodus Simple (Einfach), um die Baumstrukturansicht zu öffnen, in der Sie die Felder auswählen und umbenennen können, die Sie beibehalten möchten.
- Wählen Sie in der Baumstrukturansicht folgende Felder aus: ID, FIRSTNAME (VORNAME), LASTNAME (NACHNAME), STATE (BUNDESSTAAT), company_name (Firmen_Name) und EMAIL E-MAIL.
-
Klicken Sie auf das jeweils nebenstehende Symbol
 und benennen Sie die Felder um: ID, Firstname (Vorname), Lastname (Nachname), State (Bundesstaat), CompanyName (Firmenname) und Email (E-Mail).
und benennen Sie die Felder um: ID, Firstname (Vorname), Lastname (Nachname), State (Bundesstaat), CompanyName (Firmenname) und Email (E-Mail).
-
Klicken Sie auf das Symbol
-
Klicken Sie auf Save (Speichern), um die Konfiguration zu speichern.
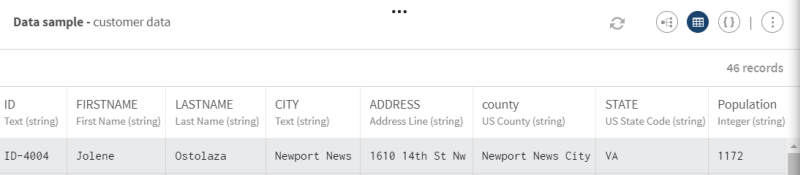
Sehen Sie sich die Vorschau des Prozessors an, um die Daten vor dem Auswahl- und Umbenennungsvorgang mit denjenigen nach dem Vorgang zu vergleichen.
-
Klicken Sie auf und fügen Sie einen Prozessor vom Typ Semantic filter (Semantischer Filter) zur Pipeline hinzu. Das Konfigurationsfenster wird geöffnet.
-
Klicken Sie auf Save (Speichern), um die Konfiguration zu speichern.
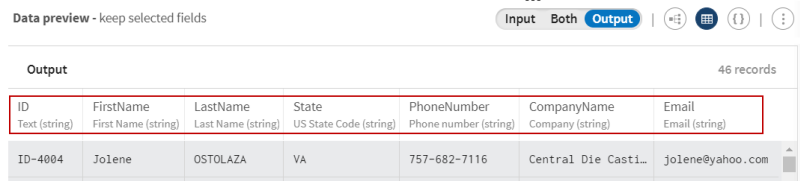
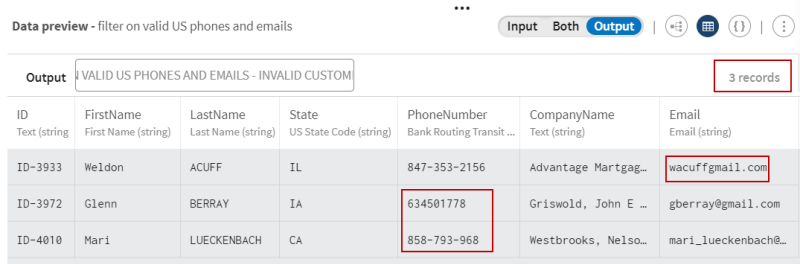
Sehen Sie sich die Vorschau des Prozessors an, um die Daten vor dem Filtervorgang mit denjenigen nach dem Vorgang zu vergleichen: Sie werden feststellen, dass ein Dateneintrag einen ungültigen E-Mail-Wert enthält (das Zeichen @ fehlt in der E-Mailadresse) und zwei Dateneinträge ungültige Telefonnummer-Werte aufweisen (fehlende Ziffern), wenn die Einträge mit den zugehörigen semantischen Typen verglichen werden.
-
Klicken Sie auf die Schaltfläche
 neben dem Prozessor vom Typ Semantic filter (Semantischer Filter) und klicken Sie auf das Element ADD DESTINATION (ZIEL HINZUFÜGEN), um den Datensatz auszuwählen der die zurückgewiesenen Daten aufnehmen soll: die Daten mit ungültigen Werten.
neben dem Prozessor vom Typ Semantic filter (Semantischer Filter) und klicken Sie auf das Element ADD DESTINATION (ZIEL HINZUFÜGEN), um den Datensatz auszuwählen der die zurückgewiesenen Daten aufnehmen soll: die Daten mit ungültigen Werten.
Ergebnisse
Die Pipeline wird ausgeführt, die Daten werden gemäß den von Ihnen ausgewählten semantischen Typen gefiltert und die Ausgabe-Flows werden an die von Ihnen angegebenen Ziele gesendet.
Nächste Maßnahme
Hat diese Seite Ihnen geholfen?
Wenn Sie Probleme mit dieser Seite oder ihren Inhalten feststellen – einen Tippfehler, einen fehlenden Schritt oder einen technischen Fehler –, teilen Sie uns bitte mit, wie wir uns verbessern können!