
Loading data from the file on S3 to Redshift
Procedure
-
Double-click tRedshiftBulkExec to open its Basic settings view on the Component tab.
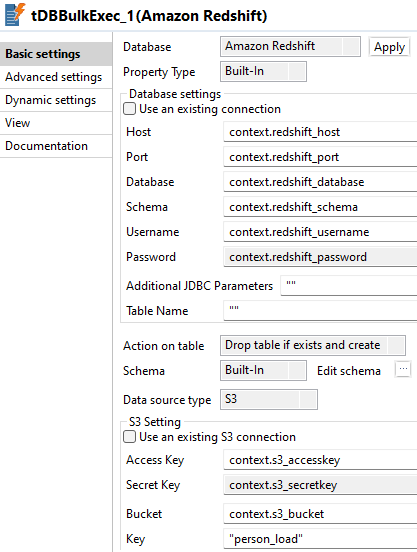
-
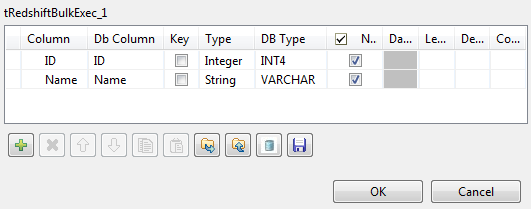
Click the [...] button next to Edit schema and in the pop-up window define the schema by
adding two columns: ID of Integer type
and Name of String type.
Did this page help you?
If you find any issues with this page or its content – a typo, a missing step, or a technical error – let us know how we can improve!