
Filtering Avro format employee data
This scenario applies only to Talend products with Big Data.
For more technologies supported by Talend, see Talend components.
This scenario illustrates how to create a Talend Map/Reduce Job to read, transform and write Avro format data by using Map/Reduce components. This Job generates Map/Reduce code and directly runs in Hadoop. In addition, the Map bar in the workspace indicates that only a mapper will be used in this Job and at runtime, it shows the progress of the Map computation.
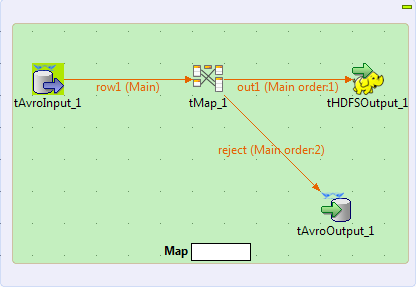
Note that the Talend Map/Reduce components are available to subscription-based Big Data users only and this scenario can be replicated only with Map/Reduce components.
1;Lyndon;Fillmore;21-05-2008
2;Ronald;McKinley;15-08-2008
3;Ulysses;Roosevelt;05-10-2008
4;Harry;Harrison;23-11-2007
5;Lyndon;Garfield;19-07-2007
6;James;Quincy;15-07-2008
7;Chester;Jackson;26-02-2008
8;Dwight;McKinley;16-07-2008
9;Jimmy;Johnson;23-12-2007
10;Herbert;Fillmore;03-04-2008
Before starting to replicate this scenario, ensure that you have appropriate rights and permissions to access the Hadoop distribution to be used. Then proceed as follows:
Did this page help you?
If you find any issues with this page or its content – a typo, a missing step, or a technical error – let us know how we can improve!