
Filtrage de données relatives à des employés au format Avro
Ce scénario s'applique uniquement aux solutions Talend avec Big Data.
Pour plus de technologies supportées par Talend, consultez Composants Talend.
Ce scénario explique comment utiliser un Job Map/Reduce Talend afin de lire, transformer et écrire des données au format Avro à l'aide de composants Map/Reduce. Ce Job génère du code Map/Reduce et s'exécute directement dans Hadoop. De plus, la barre Map dans l'espace de modélisation graphique indique que seule une opération de mapping est utilisée pour ce Job. À la génération, la barre montre la progression de l'opération de mapping.
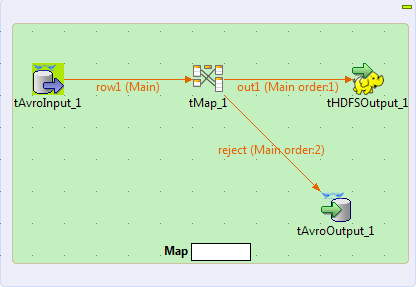
Notez que les composants Map/Reduce de Talend ne sont disponibles que pour les utilisateurs et utilisatrices ayant souscrit à une offre Big Data et que ce scénario ne peut être reproduit qu'avec des composants Map/Reduce.
1;Lyndon;Fillmore;21-05-2008
2;Ronald;McKinley;15-08-2008
3;Ulysses;Roosevelt;05-10-2008
4;Harry;Harrison;23-11-2007
5;Lyndon;Garfield;19-07-2007
6;James;Quincy;15-07-2008
7;Chester;Jackson;26-02-2008
8;Dwight;McKinley;16-07-2008
9;Jimmy;Johnson;23-12-2007
10;Herbert;Fillmore;03-04-2008
Avant de commencer à reproduire ce scénario, assurez-vous d'avoir les droits d'accès appropriés à la distribution Hadoop à utiliser. Procédez comme suit :
Cette page vous a-t-elle aidé ?
Si vous rencontrez des problèmes sur cette page ou dans son contenu – une faute de frappe, une étape manquante ou une erreur technique – dites-nous comment nous améliorer !