
Applying a preparation to a data sample in an Apache Spark Streaming Job
This scenario applies only to Talend Real Time Big Data Platform and Talend Data Fabric.
For more technologies supported by Talend, see Talend components.
The tDataprepRun component allows you to reuse an existing preparation made in Talend Data Preparation or Talend Cloud Data Preparation, directly in a Big Data Job. In other words, you can operationalize the process of applying a preparation to input data with the same model.
The following scenario creates a simple Job that :
- Reads a small sample of customer data,
- applies an existing preparation on this data,
- shows the result of the execution in the console.
This assumes that a preparation has been created beforehand, on a dataset with the same schema as your input data for the Job. In this case, the existing preparation is called datapreprun_spark.
This simple preparation puts the customer last names into upper case and applies a filter to isolate the customers from California, Texas and Florida.
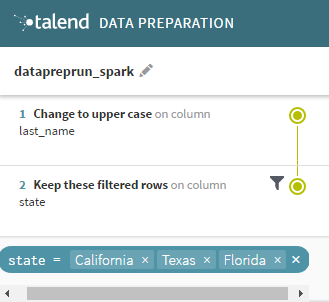
Note that if a preparation contains actions that only affect a single row, or cells, they will be skipped by the tDataprepRun component during the job. The Make as header or Delete Row functions for example, do not work in a Big Data context.
James;Butt;California
Daniel;Fox;Connecticut
Donna;Coleman;Alabama
Thomas;Webb;Illinois
William;Wells;Florida
Ann;Bradley;California
Sean;Wagner;Florida
Elizabeth;Hall;Minnesota
Kenneth;Jacobs;Florida
Kathleen;Crawford;Texas
Antonio;Reynolds;California
Pamela;Bailey;Texas
Patricia;Knight;Texas
Todd;Lane;New Jersey
Dorothy;Patterson;Virginia
tHDFSConfiguration is used in this scenario by Spark to connect to the HDFS system where the jar files dependent on the Job are transferred.
-
Yarn mode (Yarn client or Yarn cluster):
-
When using Google Dataproc, specify a bucket in the Google Storage staging bucket field in the Spark configuration tab.
-
When using HDInsight, specify the blob to be used for Job deployment in the Windows Azure Storage configuration area in the Spark configuration tab.
- When using Altus, specify the S3 bucket or the Azure Data Lake Storage for Job deployment in the Spark configuration tab.
- When using Qubole, add a tS3Configuration to your Job to write your actual business data in the S3 system with Qubole. Without tS3Configuration, this business data is written in the Qubole HDFS system and destroyed once you shut down your cluster.
-
When using on-premises distributions, use the configuration component corresponding to the file system your cluster is using. Typically, this system is HDFS and so use tHDFSConfiguration.
-
-
Standalone mode: use the configuration component corresponding to the file system your cluster is using, such as tHDFSConfiguration Apache Spark Batch or tS3Configuration Apache Spark Batch.
If you are using Databricks without any configuration component present in your Job, your business data is written directly in DBFS (Databricks Filesystem).
Prerequisite: ensure that the Spark cluster has been properly installed and is running.
Did this page help you?
If you find any issues with this page or its content – a typo, a missing step, or a technical error – let us know how we can improve!