
Analyzing a Twitter flow in near real-time
This scenario applies only to Talend Real Time Big Data Platform and Talend Data Fabric.
For more technologies supported by Talend, see Talend components.
In this scenario, you create a Spark Streaming Job to analyze, at the end of each 15-second interval, which hashtags are most used by Twitter users when they mention Paris in their Tweets over the previous 20 seconds.
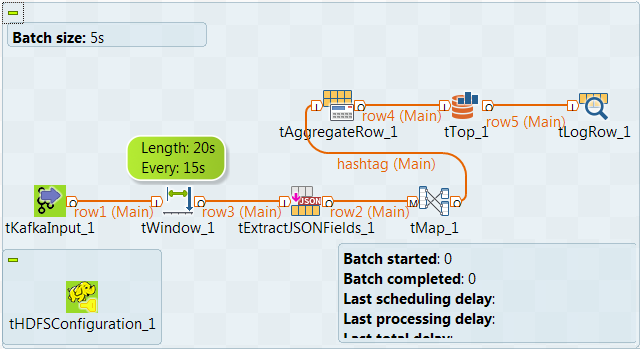
An open source third-party program is used to receive and write Twitter streams in a given Kafka topic, twitter_live for example, and the Job you design in this scenario is used to consume the Tweets from this topic.
A row of Twitter raw data with hashtags reads like the example presented at https://dev.twitter.com/overview/api/entities-in-twitter-objects#hashtags.
Before replicating this scenario, you need to ensure that your Kafka system is up and running and you have proper rights and permissions to access the Kafka topic to be used. You also need a Twitter-streaming program to transfer Twitter streams into Kafka in near real-time. Talend does not provide this kind of program but some free programs created for this purpose are available in some online communities such as Github.
tHDFSConfiguration is used in this scenario by Spark to connect to the HDFS system where the jar files dependent on the Job are transferred.
-
Yarn mode (Yarn client or Yarn cluster):
-
When using Google Dataproc, specify a bucket in the Google Storage staging bucket field in the Spark configuration tab.
-
When using HDInsight, specify the blob to be used for Job deployment in the Windows Azure Storage configuration area in the Spark configuration tab.
- When using Altus, specify the S3 bucket or the Azure Data Lake Storage for Job deployment in the Spark configuration tab.
- When using Qubole, add a tS3Configuration to your Job to write your actual business data in the S3 system with Qubole. Without tS3Configuration, this business data is written in the Qubole HDFS system and destroyed once you shut down your cluster.
-
When using on-premises distributions, use the configuration component corresponding to the file system your cluster is using. Typically, this system is HDFS and so use tHDFSConfiguration.
-
-
Standalone mode: use the configuration component corresponding to the file system your cluster is using, such as tHDFSConfiguration Apache Spark Batch or tS3Configuration Apache Spark Batch.
If you are using Databricks without any configuration component present in your Job, your business data is written directly in DBFS (Databricks Filesystem).
To replicate this scenario, proceed as follows:
Did this page help you?
If you find any issues with this page or its content – a typo, a missing step, or a technical error – let us know how we can improve!