
Denormalizing on multiple columns
Procedure
-
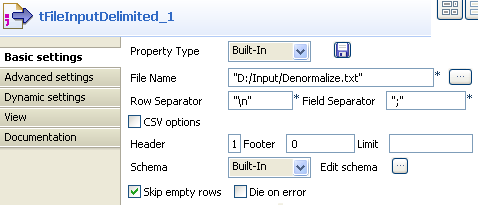
On the tFileInputDelimited
Basic settings panel, set the filepath to
the file to be denormalized.
-
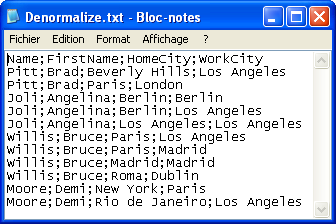
The file schema is made of four columns including: Name, FirstName, HomeTown,
WorkTown.
-
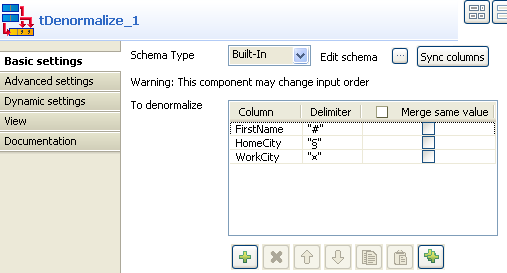
Add as many line to the table as you need using the plus
button. Then select the relevant columns in the drop-down list.
-
Save your Job and press F6 to execute it.
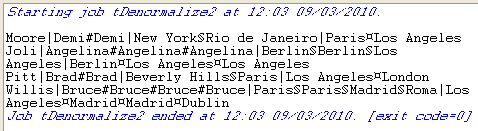 The result shows the denormalized values concatenated using a comma.
The result shows the denormalized values concatenated using a comma.
Results
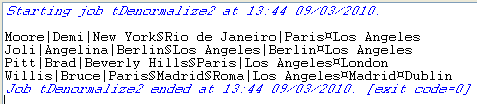
This time, the console shows the results with no duplicate instances.
Did this page help you?
If you find any issues with this page or its content – a typo, a missing step, or a technical error – let us know how we can improve!