
Best Practice: Conventions for Return Codes
Overview
As discussed in the Best Practice on Conventions for Job Entry/Exit/Return Points, Talend Jobs should have a clear methodology, structure, and defined standards on where and how a job starts and stops. Knowing the state upon entry to, exit from, or return from a Job can dramatically improve code structure, error handling, operational management, monitoring, notification, and debugging of these code modules.
Defining a common use mechanism for Job Return Codes not only deliver enterprise standards, they provide useful information about a Jobs' execution and the hand-off between other connected Jobs and/or joblets.
Talend components tDie and tWarn are discussed in more detail in the Best Practice on Design Elements for Job Components, however it is important to mention them here as they provide the means to specify the preferred Return Code from any job. These two components are also well defined in the Talend Component Reference Guide and can be found for use in the Logs & Errors palette of the Talend Studio.
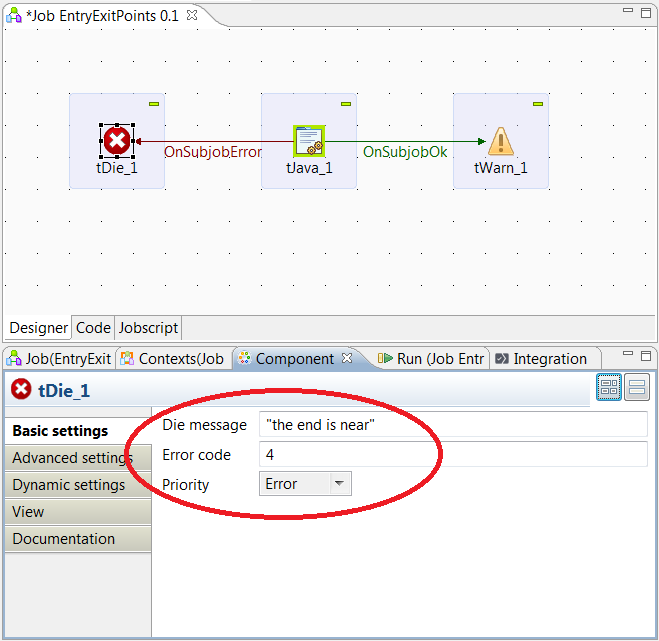
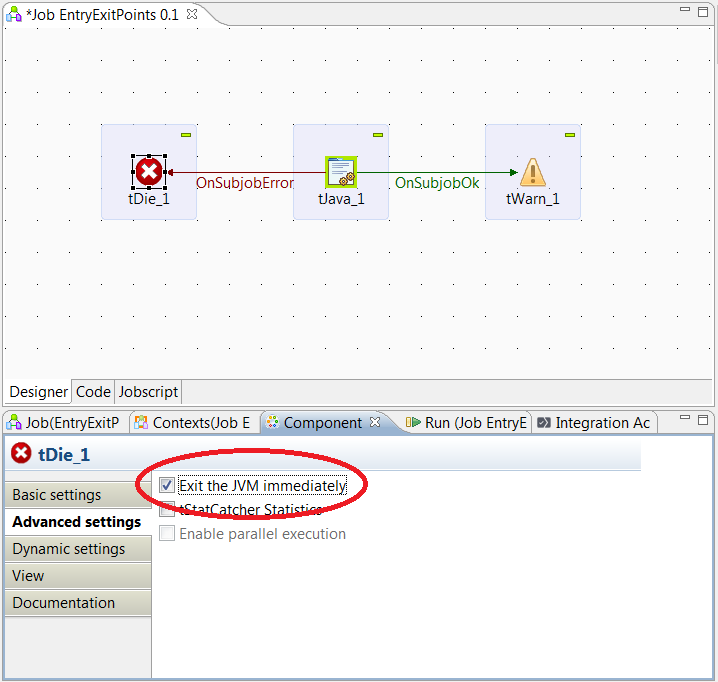
User defined messages for the tDie/tWarn components, a string value, are programmatically available in the DIE_MESSAGES and WARN_MESSAGES global variables, respectively.
tLogCatcher is a closely related component which when used, catches tDie/tWarn invocations. A failed components' generated ERROR_MESSAGE is further detailed in the Best Practice on Conventions for Logging.
Did this page help you?
If you find any issues with this page or its content – a typo, a missing step, or a technical error – let us know how we can improve!