
Simple VSR algorithm
This scenario applies only to Talend Data Management Platform, Talend Big Data Platform, Talend Real-Time Big Data Platform, Talend MDM Platform, Talend Data Services Platform, Talend MDM Platform and Talend Data Fabric.
-
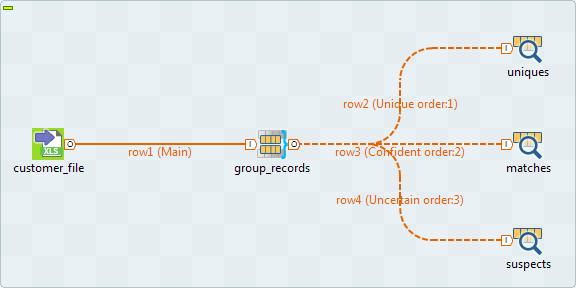
Uniques: lists the records which group size (minimal distance computed in the record) is equal to 1.
-
Matches: lists the records which group score (minimal distance computed in the record) is greater than or equal to the threshold you define in the Confident match threshold field.
-
Suspects: lists the records which group score (minimal distance computed in the record) is less than the threshold you define in the Confident match threshold field.
Did this page help you?
If you find any issues with this page or its content – a typo, a missing step, or a technical error – let us know how we can improve!