
Working with Amazon Kinesis and Big Data Streaming Jobs
This scenario applies only to Talend Real-Time Big Data Platform and Talend Data Fabric.
This example uses Talend Real-Time Big Data Platform v6.1. In addition, it uses these licensed products provided by Amazon: Amazon EC2, Amazon Kinesis, and Amazon EMR.
In this example, you will build the following Job, to read and and write data to an Amazon Kinesis stream and display results in the Console.
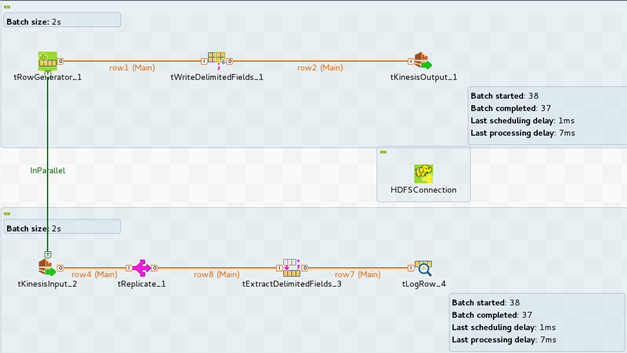
tHDFSConfiguration is used in this scenario by Spark to connect to the HDFS system where the jar files dependent on the Job are transferred.
-
Yarn mode (Yarn client or Yarn cluster):
-
When using Google Dataproc, specify a bucket in the Google Storage staging bucket field in the Spark configuration tab.
-
When using HDInsight, specify the blob to be used for Job deployment in the Windows Azure Storage configuration area in the Spark configuration tab.
- When using Altus, specify the S3 bucket or the Azure Data Lake Storage for Job deployment in the Spark configuration tab.
-
When using on-premises distributions, use the configuration component corresponding to the file system your cluster is using. Typically, this system is HDFS and so use tHDFSConfiguration.
-
-
Standalone mode: use the configuration component corresponding to the file system your cluster is using, such as tHDFSConfiguration Apache Spark Batch or tS3Configuration Apache Spark Batch.
If you are using Databricks without any configuration component present in your Job, your business data is written directly in DBFS (Databricks Filesystem).