
Writing data to an Amazon Kinesis Stream
Before you begin
In this section, it is assumed that you have an Amazon EMR cluster up and running and that you have created the corresponding cluster connection metadata in the repository. It is also assumed that you have created an Amazon Kinesis stream.
Procedure
-
Create a Big Data Streaming Job using the Spark framework.
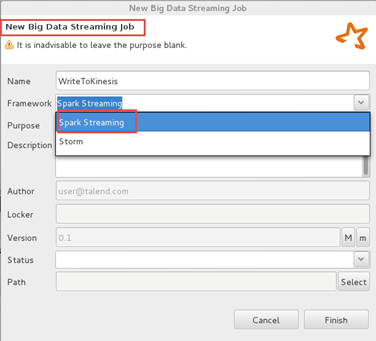
-
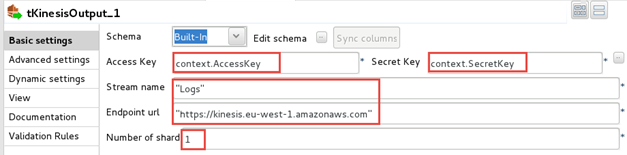
Provide the number of shards, as specified when you created the Kinesis
stream.
Did this page help you?
If you find any issues with this page or its content – a typo, a missing step, or a technical error – let us know how we can improve!