
Dropping and linking Spark components
You orchestrate the Spark Batch components in the Job workspace in
order to design a data transformation process that runs in the Apache Spark Batch
framework.
Before you begin
-
You have launched Talend Studio and opened the Integration perspective.
-
An empty Job has been created as described in Creating the Spark Batch Job and is open in the workspace.
Procedure
Results
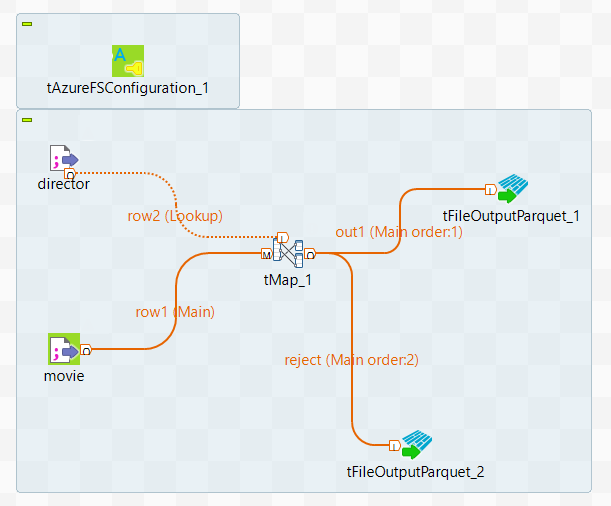
In the workspace, the whole Job looks like this:
Did this page help you?
If you find any issues with this page or its content – a typo, a missing step, or a technical error – let us know how we can improve!