
Uploading files to DBFS (Databricks File System)
Uploading a file to DBFS allows the big data Jobs to read and process it. DBFS is the Big Data file system to be used in this example.
In this procedure, you will create a Job that writes data in your DBFS system. For the files needed for the use case, download tpbd_gettingstarted_source_files.zip from the Downloads tab in the left panel of this page.
Procedure
-
Right click tDBFSConnection and from the contextual menu that is displayed, select .
Example
-
Double-click tDBFSConnection to open its Component view.
Example
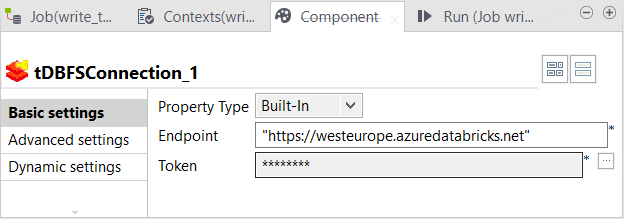
-
Double-click tDBFSPut to open its Component view.
Example
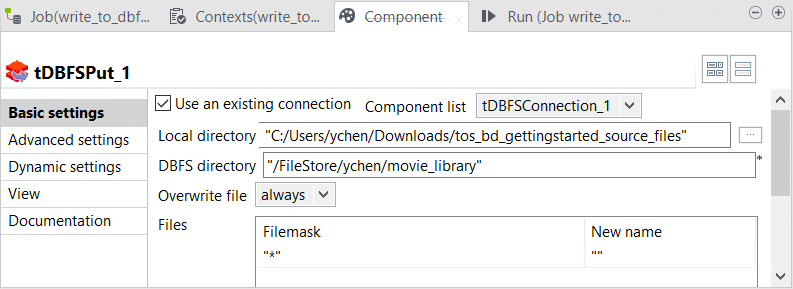
-
Press F6 to run the Job.
The RunThe files about movies and their directors are stored in this view is opened automatically. It shows the progress of this Job.
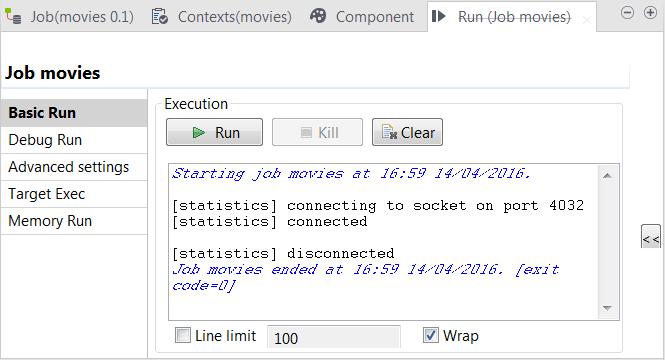
Results
When the Job is done, the files you uploaded can be found in DBFS in the directory you have specified.
Did this page help you?
If you find any issues with this page or its content – a typo, a missing step, or a technical error – let us know how we can improve!