
Displaying the match results
About this task
To collect duplicates from the input flow according to the match types you define, Levenshtein and Jaro-Winkler in this example, do the following:
Procedure
-
Save the settings in the match analysis editor and press F6.
The analysis is executed. The match rule and blocking key are computed against the whole dataset and the Analysis Results view is open in the editor.
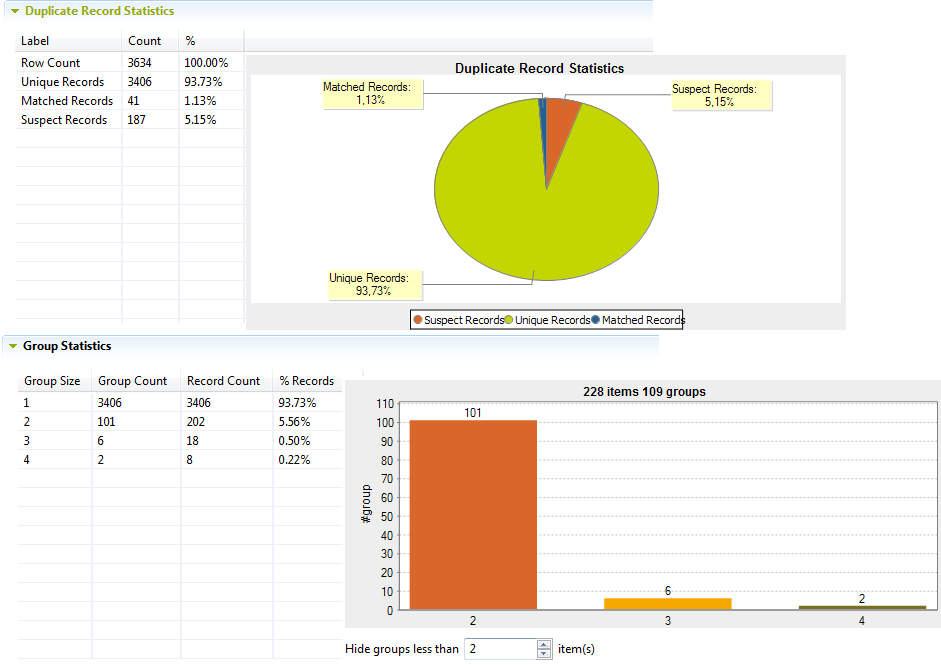 In this view, the charts give a global picture about the duplicates in the analyzed data. In the first tables, you can read statistics about the count of processed records, distinct records with only one occurrence, duplicate records (matched records) and suspect records that did not match the rule. Duplicate records represent the records that matched with a good score - above the confidence threshold. One record of the matched pair is a duplicate that should be discarded and the other is the survivor record.In the second table, you can read statistics about the number of groups and the number of records in each group. You can click any column header in the table to sort the results accordingly.
In this view, the charts give a global picture about the duplicates in the analyzed data. In the first tables, you can read statistics about the count of processed records, distinct records with only one occurrence, duplicate records (matched records) and suspect records that did not match the rule. Duplicate records represent the records that matched with a good score - above the confidence threshold. One record of the matched pair is a duplicate that should be discarded and the other is the survivor record.In the second table, you can read statistics about the number of groups and the number of records in each group. You can click any column header in the table to sort the results accordingly.
Did this page help you?
If you find any issues with this page or its content – a typo, a missing step, or a technical error – let us know how we can improve!