
Querying the Snowflake API and sending the data to Google Cloud Storage
Before you begin
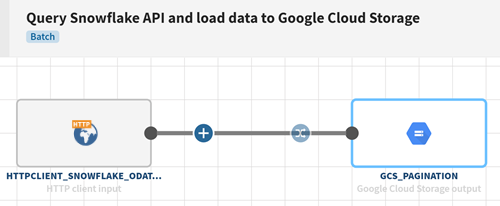
Procedure
-
Fill in the connection properties and URL address of the API to be invoked as
described in HTTP Client properties:
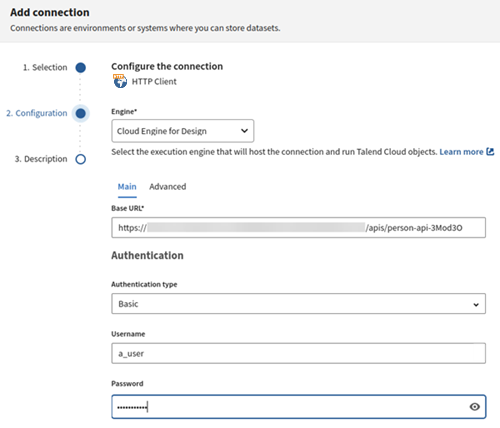
- Base URL: copy-paste the Base URL provided in the Snowflake API summary.
- Authentication type: Select Basic.
- Enter the credentials (username and password) necessary to connect to the API.
- Check the connection and click Next.
-
Name your dataset, and fill in the required properties to create your Google Cloud
Storage blob in your existing bucket:
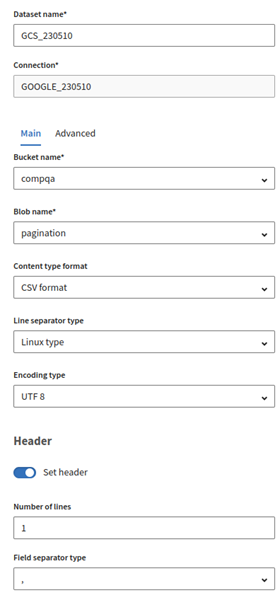
- Bucket name: select an existing bucket name.
- Blob name: enter a name that does not exist yet.
- Content type format: select CSV format.
- Line separator type: select Linux type.
- Encoding type: select UTF-8.
- Enable the Set header option, and enter 1 in Number of lines and , in Field separator type.
Results
Your pipeline is being executed. All rows from the 11th row of the Snowflake table are copied into a file in Google Cloud Storage, and rows are retrieved 5 by 5 through the ODATA API.
Did this page help you?
If you find any issues with this page or its content – a typo, a missing step, or a technical error – let us know how we can improve!