
Writing data to a cloud file storage (S3)
Before you begin
-
Make sure your user or user group has the correct permissions to access the Amazon S3 resources.
If you do not have these permissions you can try one of the following options.- (recommended) Ask the administrator who manages your Amazon account to give you/your user the correct S3 permissions.
- Implement your access policy yourself by following the Amazon documentation if you are allowed to do so.
- (not recommended) Attach the AmazonS3FullAccess policy to your group/your user through the IAM console. This allows you to read and write to S3 resources without restrictions to a specific bucket. However this is a quick fix that is not recommended by Talend.
Information noteNote: The default error that displays when trying to access S3 resources without sufficient permissions is Bad Gateway. -
Download the file: financial_transactions.avro file.
- Create a Remote Engine Gen2 and its run profile from Talend Management Console.
The Cloud Engine for Design and its corresponding run profile come embedded by default in Talend Management Console to help users quickly get started with the app, but it is recommended to install the secure Remote Engine Gen2 for advanced processing of data.
Procedure
-
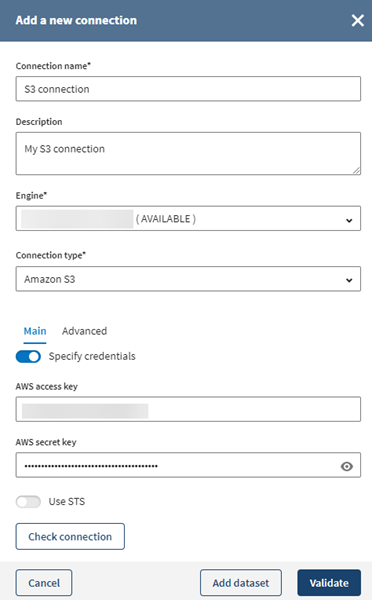
Select S3 connection in
the Connection type list.
-
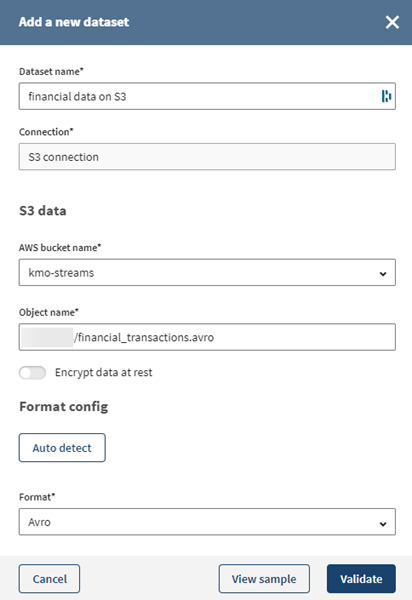
Click View sample to check that your data is valid and can
be previewed.
Results
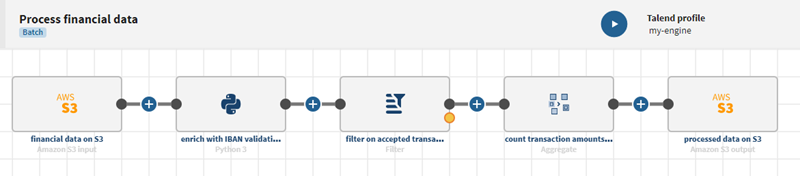
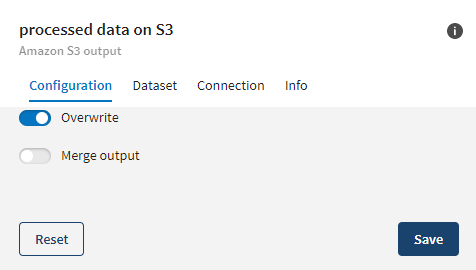
Once your pipeline is executed, the updated data will be visible in the file located on Amazon S3.
Did this page help you?
If you find any issues with this page or its content – a typo, a missing step, or a technical error – let us know how we can improve!