
Schreiben von Daten in eine cloudbasierte File Storage (S3)
Vorbereitungen
-
Stellen Sie sicher, dass Benutzer oder Benutzergruppen über die korrekten Berechtigungen für den Zugriff auf die Amazon S3-Ressourcen verfügen.
Wenn Sie nicht über diese Berechtigungen verfügen, können Sie eine der folgenden Optionen ausprobieren.- (Empfohlen) Bitten Sie den Administrator, der Ihr Amazon-Konto verwaltet, Ihnen/Ihrem Benutzer die korrekten S3-Berechtigungen zu erteilen.
- Implementieren Sie Ihre Zugriffsrichtlinie selbst, indem Sie die Angaben in der Amazon-Dokumentation befolgen, wenn Sie dazu berechtigt sind.
- (Nicht empfohlen) Fügen Sie die AmazonS3FullAccess-Richtlinie Ihrer Gruppe bzw. Ihren Benutzern über die IAM-Konsole hinzu. Auf diese Weise können Sie ohne Beschränkung auf ein bestimmtes Bucket S3-Ressourcen lesen und in diese schreiben. Dies ist jedoch eine schnelle Lösung, die von Talend nicht empfohlen wird.
InformationshinweisAnmerkung: Der Standardfehler, der angezeigt wird, wenn Sie versuchen, auf S3-Ressourcen zuzugreifen, ohne über die erforderlichen Berechtigungen zu verfügen, ist Bad Gateway (Ungültiges Gateway). -
Laden Sie folgende Datei herunter: financial_transactions.avro
- Erstellen Sie eine Remote Engine Gen2 sowie das zugehörige Ausführungsprofil über Talend Management Console.
In Talend Management Console sind standardmäßig die Cloud Engine for Design und ein entsprechendes Ausführungsprofil integriert. Dadurch können die Benutzer in kürzester Zeit ihre Arbeit mit der Anwendung aufnehmen. Es wird jedoch empfohlen, die sichere Remote Engine Gen2 zu installieren, die eine erweiterte Datenverarbeitung ermöglicht.
Prozedur
-
Klicken Sie auf View sample (Sample anzeigen), um zu prüfen, ob die Daten gültig sind und in der Vorschau angezeigt werden können.
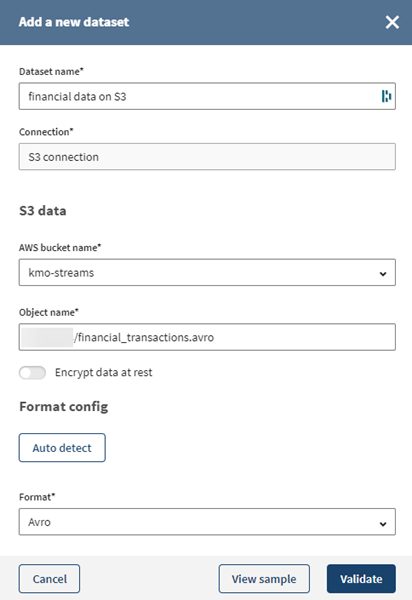
Ergebnisse
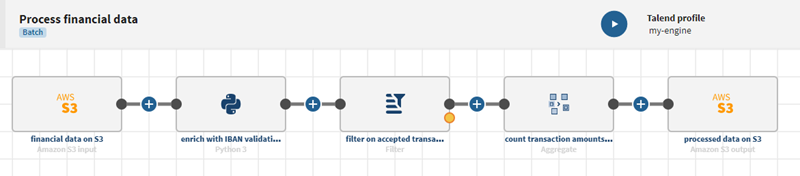
Sobald die Pipeline ausgeführt wird, sind die aktualisierten Daten in der Datei in Amazon S3 sichtbar.
Hat diese Seite Ihnen geholfen?
Wenn Sie Probleme mit dieser Seite oder ihren Inhalten feststellen – einen Tippfehler, einen fehlenden Schritt oder einen technischen Fehler –, teilen Sie uns bitte mit, wie wir uns verbessern können!