
Lire des lignes complètes dans un fichier délimité
Procédure
-
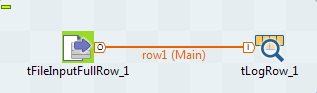
Reliez le tFileInputFullRow au tLogRow à l'aide d'un lien Row > Main..
-
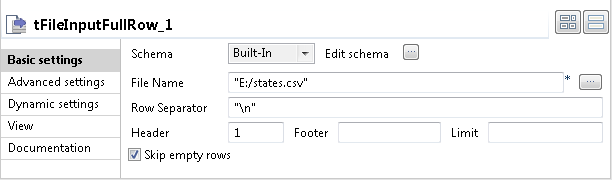
Double-cliquez sur le tFileInputFullRow pour ouvrir sa vue Basic settings dans l'onglet Component.
-
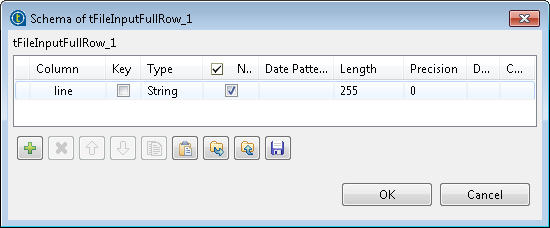
Cliquez sur le bouton [...] du champ Edit schema pour voir les données à transférer au composant tLogRow. Notez que le schéma est en lecture seule et ne comporte qu'une seule colonne, line.
-
Double-cliquez sur le tLogRow pour ouvrir sa vue Basic settings dans l'onglet Component.
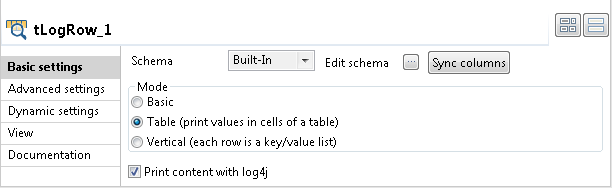 Dans la zone Mode, sélectionnez Table (print values in cells of a table) pour afficher un résultat plus lisible.
Dans la zone Mode, sélectionnez Table (print values in cells of a table) pour afficher un résultat plus lisible. -
Appuyez sur Ctrl+S pour sauvegarder votre Job puis sur F6 pour l'exécuter.
 Comme affiché ci-dessus, les dix lignes de données du fichier states.csv sont lues une par une, en ignorant les séparateurs de champs, et les lignes de données complètes sont affichées dans la console.Pour extraire les champs des lignes, vous devez utiliser un tExtractDelimitedFields, un tExtractPositionalFields ou un tExtractRegexFields. Pour plus d'informations, consultez tExtractDelimitedFields, tExtractPositionalFields et tExtractRegexFields.
Comme affiché ci-dessus, les dix lignes de données du fichier states.csv sont lues une par une, en ignorant les séparateurs de champs, et les lignes de données complètes sont affichées dans la console.Pour extraire les champs des lignes, vous devez utiliser un tExtractDelimitedFields, un tExtractPositionalFields ou un tExtractRegexFields. Pour plus d'informations, consultez tExtractDelimitedFields, tExtractPositionalFields et tExtractRegexFields.
Cette page vous a-t-elle aidé ?
Si vous rencontrez des problèmes sur cette page ou dans son contenu – une faute de frappe, une étape manquante ou une erreur technique – dites-nous comment nous améliorer !