
Concevoir le Job et configurer les données d'entrée
Procédure
-
Dans le nœud Embedded Rules de la vue Repository, déposez le modèle de règle créé.
 Un composant tRules s'affiche dans l'espace de modélisation graphique, avec le modèle de règle embarqué.
Un composant tRules s'affiche dans l'espace de modélisation graphique, avec le modèle de règle embarqué. -
Double-cliquez sur le tFixedFlowInput pour afficher sa vue Component et définir ses propriétés.

-
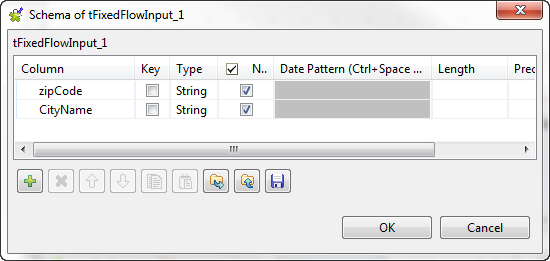
Cliquez sur le bouton [...] à côté du champ Edit schema pour ouvrir l'éditeur du schéma.
Cette page vous a-t-elle aidé ?
Si vous rencontrez des problèmes sur cette page ou dans son contenu – une faute de frappe, une étape manquante ou une erreur technique – dites-nous comment nous améliorer !