
L'approche de l'apprentissage automatique
L'approche de l'apprentissage automatique est utile lorsque vous souhaitez mettre en correspondance un important volume de données.
Le processus de rapprochement des données peut être automatisé en construisant un modèle permettant de prédire les correspondances.
Le processus de rapprochement de données
Les avantages de l'apprentissage automatique sur l'approche classique sont les suivants :
- Les différents mécanismes de blocking permettent une augmentation de la vitesse du calcul et une montée en charge. Dans le cadre de l'apprentissage automatique, le blocking est différent du partitionnement : un enregistrement peut appartenir à plusieurs blocs et la taille des blocs est clairement délimitée, ce n'est pas nécessairement le cas lors de l'utilisation du composant tGenKey.
- Les règles apprises et stockées par le modèle d'apprentissage automatique peuvent être plus complexes et moins arbitraires que les règles de rapprochement définies manuellement.
- La configuration des composants est plus simple. Le modèle de rapprochement apprend automatiquement les distances de correspondance et les seuils de similarité, entre autres.
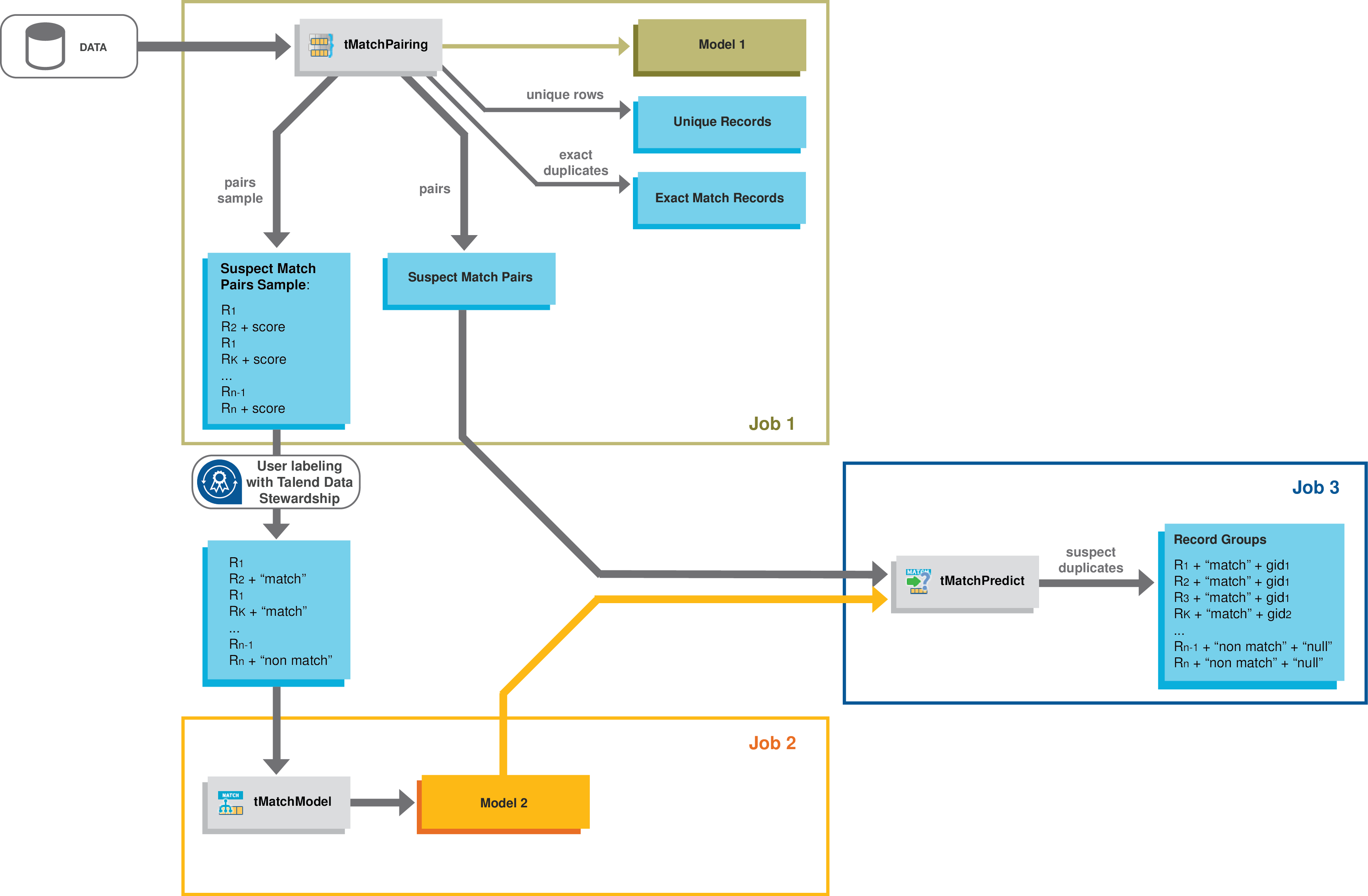
- La première étape consiste en une pré-analyse du jeu de données à l'aide du tMatchPairing. Les enregistrements uniques, les enregistrements correspondant exactement, les paires suspectes et un échantillon des paires suspectes sont écrits en sortie par le tMatchPairing.
Pour plus d'exemples, consultez Calculer des paires suspectes et écrire un échantillon dans Talend Data Stewardship (uniquement en anglais) et Calculer des paires suspectes et des échantillons suspects depuis les données source (uniquement en anglais).
- La deuxième étape consiste à libeller manuellement les paires suspectes en tant que "match" ou "no-match". Vous pouvez utiliser Talend Data Stewardship pour libeller les paires suspectes plus facilement.
Vous pouvez utiliser une ou plusieurs classes, par exemple “match”, “potential match” et “different”.
Pour plus d'informations concernant la gestion des tâches de regroupement pour décider des relations entre les paires d'enregistrements dans Talend Data Stewardship, consultez Exemples d'utilisation de Talend Data Stewardship.
Pour plus d'informations concernant les tâches de regroupement dans Talend Data Stewardship, consultez la documentation en ligne sur la gestion des tâches de regroupement pour décider des relations entre les paires d'enregistrements sur Talend Help Center (https://help.talend.com (uniquement en anglais)).
- La troisième consiste à soumettre les paires suspectes que vous avez libellées au tMatchModel afin d'apprendre et de générer un modèle de classification.
Pour des exemples de générations de modèles de rapprochement, consultez les scénarios (uniquement en anglais).
Vous trouverez des exemples de générations de modèles de rapprochement sur Talend Help Center (https://help.talend.com (uniquement en anglais)).
- La quatrième étape consiste à libeller les paires suspectes dans des jeux de données volumineux automatiquement en utilisant, avec le tMatchPredict, le modèle calculé par le tMatchModel.
Pour voir un exemple de procédure pour libeller des paires suspectes avec des libellés assignés, consultez le scénario (uniquement en anglais).
Vous trouverez un exemple de la façon dont vous pouvez libeller des paires suspectes avec des libellés assignés sur Talend Help Center (https://help.talend.com (uniquement en anglais)).
Qu'est-ce qu'un bon échantillon ?
L'échantillon doit être équilibré : le nombre d'enregistrements dans chaque classe - "match" et "no match" - doit être approximativement le même. Un échantillon déséquilibré aboutit à un modèle insatisfaisant.
L'échantillon doit être diversifié : plus les exemples sont diversifiés, plus les règles apprises par le modèles seront efficaces.
L'échantillon doit avoir la bonne taille : si vous disposez d'un important jeu de données constitué de millions d'enregistrements, quelques centaines ou milliers d'exemples peuvent suffire. Si votre jeu de données est constitué de moins de 10 000 enregistrements, la taille de l'échantillon doit se situer entre 1 et 10 % du jeu de données total.
Comment le tMatchModel génère-t-il un modèle ?
L'algorithme d'apprentissage automatique calcule différentes mesures, appelées attributs, afin d'obtenir le plus d'informations possibles sur les colonnes choisies.
Pour générer le modèle, le tMatchModel analyse les données en utilisant l'algorithme Random Forest. Une forêt aléatoire (random forest) est une collection d'arbres de décision utilisée pour résoudre un problème de classifications. Dans un arbre de décision, chaque nœud correspond à une question sur les attributs associés aux données d'entrée. Une forêt aléatoire génère plusieurs arbres de décision afin d'améliorer la précision de la classification et de générer un modèle.
Pour plus d'informations concernant le rapprochement de données dans Apache Spark, consultez les propriétés du tMatchModel (uniquement en anglais).
Cette page vous a-t-elle aidé ?
Si vous rencontrez des problèmes sur cette page ou dans son contenu – une faute de frappe, une étape manquante ou une erreur technique – dites-nous comment nous améliorer !