
Configurer le composant tMatchGroup
Procédure
-
Cliquez sur le bouton Chart afin d'exécuter le Job dans la configuration définie. Les résultats de la correspondance s'affichent directement dans l'assistant.
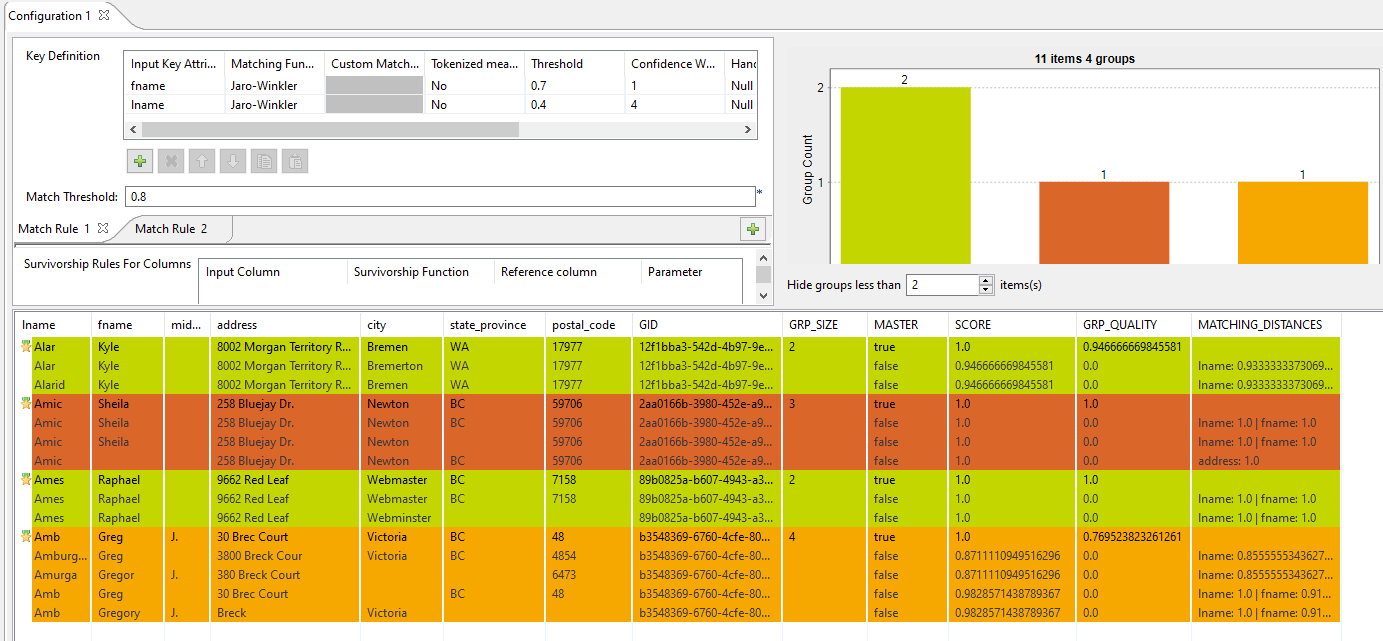 Le diagramme de rapprochement donne une vue globale des doublons dans les données analysées. La table des correspondances donne les détails des éléments de chaque groupe et les colore selon leur couleur dans le graphique des correspondances.Le Job effectue une opération de mise en correspondance de type OR. Il évalue les enregistrements par rapport à la règle. La colonne MATCHING_DISTANCES vous permet de voir la règle qui a été utilisée sur chaque enregistrement.
Le diagramme de rapprochement donne une vue globale des doublons dans les données analysées. La table des correspondances donne les détails des éléments de chaque groupe et les colore selon leur couleur dans le graphique des correspondances.Le Job effectue une opération de mise en correspondance de type OR. Il évalue les enregistrements par rapport à la règle. La colonne MATCHING_DISTANCES vous permet de voir la règle qui a été utilisée sur chaque enregistrement.Par exemple, dans le second groupe de données (brique rouge), le dernier enregistrement Amic est mis en correspondance par rapport à la seconde règle, en utilisant address1 comme attribut de clé. Les autres enregistrements du groupe, en revanche, ont mis en correspondance par rapport à la première règle utilisant lname et fname comme attributs de clés.
Comme vous pouvez le constater, la valeur de la colonne GRP_QUALITY peut être inférieure à la valeur du paramètre Match Threshold. Cela est possible car un groupe est créé à partir de paires d'enregistrements avec un score de rapprochement supérieur ou égal à la valeur de Match Threshold, mais les enregistrements ne sont pas tous comparés les uns aux autres, tandis que GRP_QUALITY prend en compte toutes les paires d'enregsitrements dans le groupe.
Cette page vous a-t-elle aidé ?
Si vous rencontrez des problèmes sur cette page ou dans son contenu – une faute de frappe, une étape manquante ou une erreur technique – dites-nous comment nous améliorer !