
Workflow du tDataprepRun dans un Job Talend
Dans le Studio Talend, lorsque vous exécutez un Job à l'aide du composant tDataprepRun, plusieurs éléments entrent en jeu pour que les données préparées dans Talend Data Preparation soient récupérées et utilisées dans le flux du Job.
Les diagrammes ci-dessous montrent la séquence d'événements se produisant lors de l'exécution, lorsque le composant tDataprepRun est utilisé pour récupérer une préparation dans un Job d'intégration de données Talend, ainsi que dans un Job Big Data. Dans les deux cas, l'utilisateur ou l'utilisatrice doit d'abord créer un Job incluant le composant tDataprepRun.
Il est recommandé d'utiliser le composant tDataprepRun avec plusieurs versions de la préparation pour que vos Jobs restent valides et pour vous garantir d'obtenir le résultat escompté, vous assurant que les étapes de préparation soient toujours les mêmes. Cette utilisation permet d'éviter que le schéma de votre préparation change sans que ceux des autres composants n'évoluent, ce qui endommagerait le Job.
Le tDataprepRun dans un Job d'intégration de données
Lorsque vous exécutez une préparation dans le flux d'un Job d'intégration de données, cette préparation est lancée directement sur le serveur Talend Data Preparation.
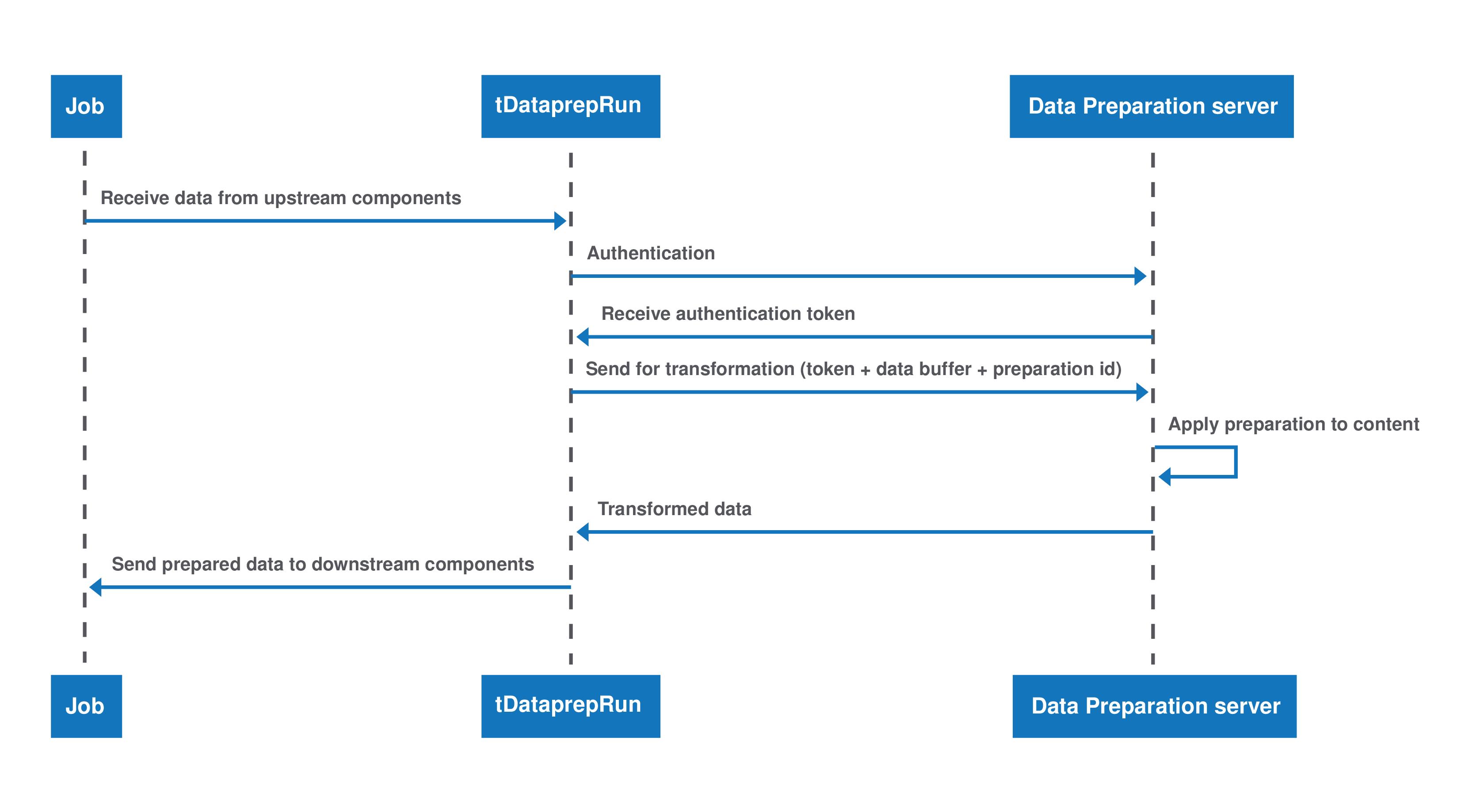
Le tDataprepRun dans un Job Big Data Spark Batch ou Spark Streaming
Lorsque vous exécutez une préparation dans le flux d'un Job Big Data, la définition de cette préparation est récupérée depuis le serveur Talend Data Preparation puis lancée sur un cluster Big Data au moment de l'exécution.

Cette page vous a-t-elle aidé ?
Si vous rencontrez des problèmes sur cette page ou dans son contenu – une faute de frappe, une étape manquante ou une erreur technique – dites-nous comment nous améliorer !