
Exécuter l'analyse avec différentes distributions de probabilités
Procédure
-
Exécutez le Job en sélectionnant la distribution Geometric distribution, puis cliquez sur Chart dans Profiling pour afficher les doublons générés par la distribution Geometric distribution sélectionnée.
Le tableau ci-dessous présente la manière dont divergent les résultats des doublons générés, selon la distribution de probabilité sélectionnée dans le composant tDuplicateRow.
Distribution de probabilité
Résultats des doublons
Description
Bernoulli distribution
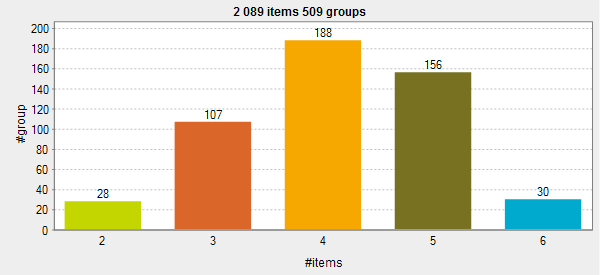
La courbe est symétrique. Les groupes de doublons sont distribués équitablement de chaque côté de la valeur moyenne, 4 dans cet exemple. Cette valeur moyenne est le nombre moyen de doublons dans un groupe de doublons et est la valeur définie dans le champ Average group size dans la vue Basic settings du composant tDuplicateRow.
Poisson distribution
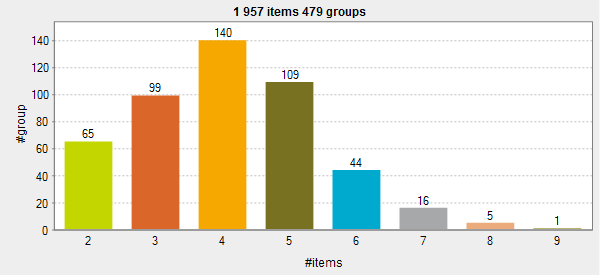
La courbe n'est pas symétrique. Les groupes de doublons ne sont pas distribués équitablement.
Geometric distribution
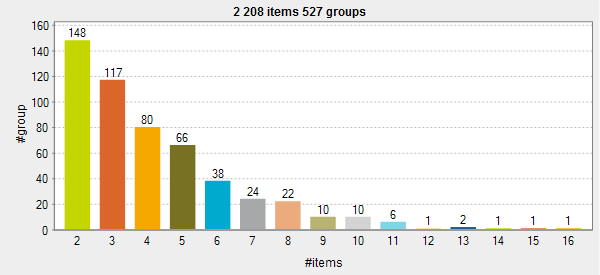
La forme de cette courbe est définie par le pourcentage configuré pour les enregistrements en doublon dans la vue Basics settings du tDuplicateRow. Plus le pourcentage est haut, moins il y aura de groupes, mais ils contiendront plus d'enregistrements.
Dans cet exemple, le pourcentage pour les enregistrements en doublon est configuré à 80%. C'est la raison pour laquelle il y a de nombreux groupes avec deux enregistrements en doublon générés (148 groupes), alors qu'il n'y a qu'un groupe avec 14, 15 et 16 doublons.
Cette page vous a-t-elle aidé ?
Si vous rencontrez des problèmes sur cette page ou dans son contenu – une faute de frappe, une étape manquante ou une erreur technique – dites-nous comment nous améliorer !