
Configurer la connexion au service S3 à utiliser dans Spark
Procédure
-
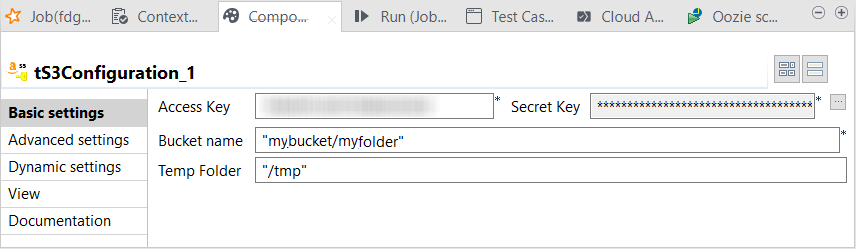
Double-cliquez sur le tS3Configuration pour ouvrir sa vue Component.
Spark utilise ce composant pour se connecter au système S3 dans lequel votre Job écrit les données métier. Si vous n'utilisez pas un composant tS3Configuration ou tout autre composant qui supporte Databricks sur AWS, ces données métier sont écrites dans le Databricks Filesystem (DBFS).
Exemple
Cette page vous a-t-elle aidé ?
Si vous rencontrez des problèmes sur cette page ou dans son contenu – une faute de frappe, une étape manquante ou une erreur technique – dites-nous comment nous améliorer !