
Lire les données d'exemple dans le Job
Procédure
-
Double-cliquez sur l'un des deux composants tHDFSInput pour afficher sa vue Basic settings.
Les deux tHDFSInput sont utilisés pour lire la même source de données et sont configurés de la même manière. Configurez-les comme décrit dans la procédure décrite dans cette section.
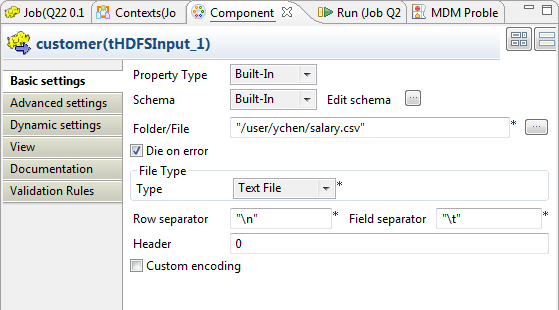
-
Cliquez trois fois sur le bouton [+] pour ajouter trois lignes et, dans la colonne Column, renommez les respectivement id, name et salary.

Cette page vous a-t-elle aidé ?
Si vous rencontrez des problèmes sur cette page ou dans son contenu – une faute de frappe, une étape manquante ou une erreur technique – dites-nous comment nous améliorer !