
Configurer les composants
Procédure
-
Double-cliquez sur le composant tFileInputDelimited pour ouvrir sa vue Basic settings.
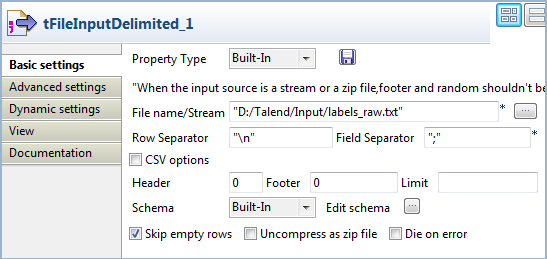
-
Cliquez sur le bouton [...] à côté du champ Edit schema afin d'ouvrir la boîte de dialogue Schema et configurez le schéma d'entrée en ajoutant une colonne nommée Tags. Cela fait, cliquez sur OK pour valider votre schéma et fermer la boîte de dialogue. Laissez les autres paramètres tels qu'ils sont.
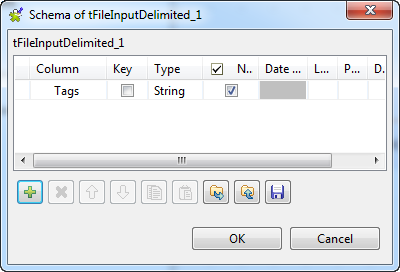
-
Double-cliquez sur le composant tNormalize pour ouvrir sa vue Basic settings.

-
Dans la vue Advanced settings, cochez les cases Get rid of duplicate rows from output, Discard the trailing empty strings et Trim resulting values.
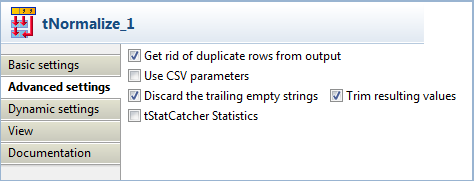
Cette page vous a-t-elle aidé ?
Si vous rencontrez des problèmes sur cette page ou dans son contenu – une faute de frappe, une étape manquante ou une erreur technique – dites-nous comment nous améliorer !