
Regrouper des lignes triées
Ce scénario Java décrit un Job à quatre composants. Il permet de lire un fichier délimité donné ligne par ligne, de trier les données d'entrée en fonction de leur type et de leur ordre, de dénormaliser toutes les lignes d'entrées triées et enfin d'afficher le résultat dans la console de la vue Run.
Pour plus de technologies supportées par Talend, consultez Composants Talend.
-
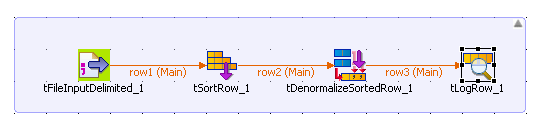
À partir de la Palette, cliquez-déposez les composants suivants dans l'espace de modélisation graphique : un tFileInputDelimited, un tSortRow, un tDenormalizeSortedRow et un tLogRow.
-
Connectez les quatre composants à l'aide de liens de type Row Main.
-
Dans l'espace de modélisation graphique, sélectionnez le composant tFileInputDelimited.
-
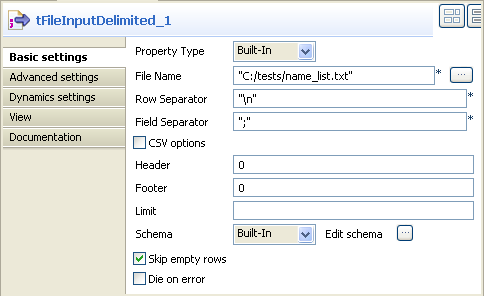
Cliquez sur la vue Component pour définir la configuration de base du tFileInputDelimited.
-
Définissez le champ Property Type en mode Built-In.
-
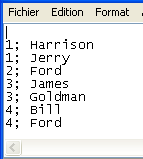
Renseignez le chemin d'accès au fichier à traiter dans le champ File Name. Dans cet exemple, on utilise le fichier name_list, qui comporte deux colonnes, id et first name.
-
Définissez si nécessaire les séparateurs de lignes et de champs, l'en-tête et le pied-de-page, ainsi que le nombre de lignes traitées.
-
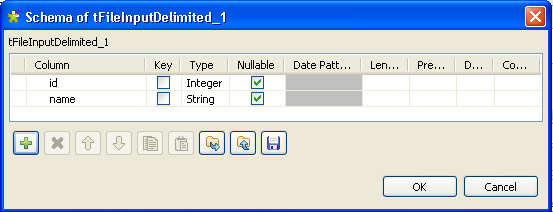
Dans la liste Schema, sélectionnez l'option Built-In et cliquez sur le bouton [...] à côté du champ Edit Schema afin de définir les données à passer au composant suivant. Dans cet exemple, le schéma est constitué de deux colonnes, id et name.
-
Dans l'espace de modélisation graphique, sélectionnez le composant tSortRow.
-
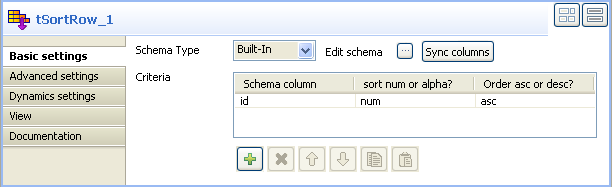
Cliquez sur la vue Component pour en définir la configuration de base du tSortRow.
-
Définissez le champ Schema Type en mode Built-In puis cliquez sur Sync columns pour récupérer le schéma à partir du composant tFileInputDelimited.
-
Dans le panneau Criteria, cliquez sur le bouton [+] pour ajouter une ligne puis définissez les paramètres de tri pour la colonne du schéma à traiter. Dans cet exemple, on veut trier la colonne id dans l'ordre croissant.
-
Dans l'espace de modélisation graphique, sélectionnez le composant tDenormalizeSortedRow.
-
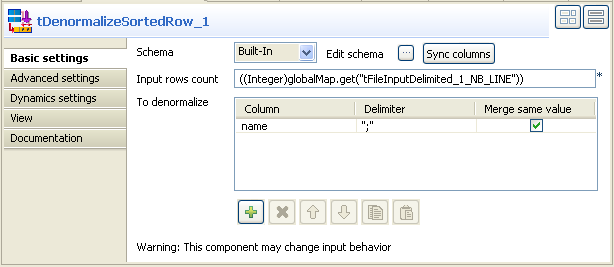
Cliquez sur la vue Component pour définir la configuration de base du tDenormalizeSortedRow.
-
Définissez le champ Schema Type en mode Built-In puis cliquez sur Sync columns pour récupérer le schéma à partir du schéma du composant tSortRow.
-
Dans le champ Input rows count, saisissez le nombre de lignes d'entrée à traiter ou cliquez simultanément sur Ctrl+Espace pour accéder à la liste des variables de contexte, puis sélectionnez la variable : tFileInputDelimited_1_NB_LINE
-
Dans le panneau To denormalize, cliquez sur le bouton [+] pour ajouter une ligne puis définissez les paramètres de la colonne à dénormaliser. Dans cet exemple, on veut dénormaliser la colonne name.
-
Dans l'espace de modélisation graphique, sélectionnez le tLogRow puis cliquez sur la vue Component pour en définir la configuration de base. Pour plus d'informations concernant les propriétés du tLogRow, consultez tLogRow.
-
Enregistrez votre Job et appuyez sur F6 pour l'exécuter.
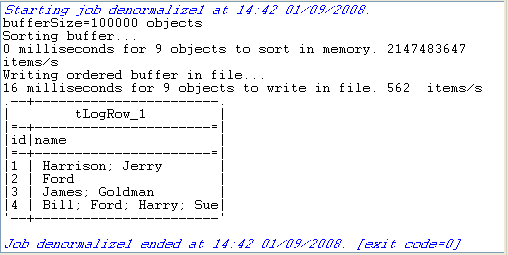
Le résultat affiché dans la console montre la façon dont la colonne name a été dénormalisée.
Cette page vous a-t-elle aidé ?
Si vous rencontrez des problèmes sur cette page ou dans son contenu – une faute de frappe, une étape manquante ou une erreur technique – dites-nous comment nous améliorer !