
Tri de données basées sur un schéma dynamique
Ce scénario s'applique à tous les produits Talend.
Pour plus de technologies supportées par Talend, consultez Composants Talend.
Dans ce scénario, des données sont triées dans un fichier d'entrée basé sur un schéma dynamique, le résultat de l'opération de tri est affiché dans la console Run, puis sauvegardé dans un fichier de sortie. Pour plus d'informations concernant la fonction de schéma dynamique, consultez le Guide d'utilisation du Studio Talend .

-
Déposez les composants requis pour ce scénario : un tFileInputDelimited, un tSortRow, un tLogRow et un tFileOutputDelimited de la Palette dans l'espace de modélisation graphique.
-
Connectez-les à l'aide de liens de type Row > Main.
-
Double-cliquez sur le composant tFileInputDelimited afin d'afficher sa vue Basic settings.
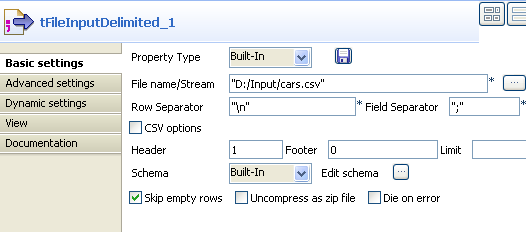
La fonctionnalité de schéma dynamique est supportée uniquement en mode Built-In et requiert une ligne d'en-tête dans le fichier d'entrée.
-
Dans la liste Property Type, sélectionnez Built-In dans la liste.
-
Cliquez sur le bouton [...] à côté du champ File Name pour sélectionner le fichier contenant les données d'entrée. Dans ce scénario, le fichier d'entrée cars.csv contient cinq colonnes : ID_Owner, Registration, Make, Color et ID_Reseller.
-
Spécifiez la ligne d'en-tête dans le champ Header. Dans ce scénario, il s'agit de la première ligne.
-
Sélectionnez Built-In dans la liste Schema, puis cliquez sur Edit schema pour paramétrer le schéma d'entrée.
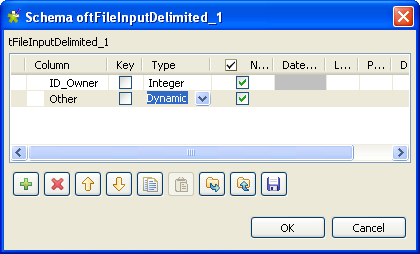
La colonne dynamique doit être définie dans la dernière ligne du schéma.
-
Dans l'éditeur de schéma, ajoutez deux colonnes et nommez-les respectivement ID_Owner et Other. Paramétrez le type de données de la colonne Other en Dynamic afin de récupérer toutes les colonnes non définies dans le schéma.
-
Cliquez sur OK pour propager le schéma et fermer l'éditeur de schéma.
-
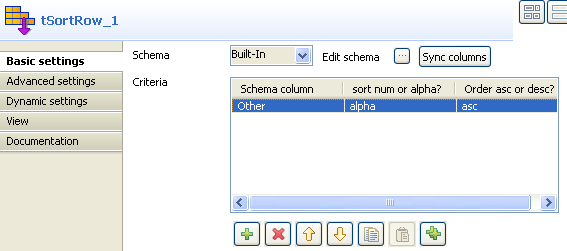
Double-cliquez sur le composant tSortRow pour afficher la vue Basic settings.
-
Ajoutez une ligne dans le tableau Criteria à l'aide du bouton [+], sélectionnez Other dans Schema column, alpha dans le type de tri, puis sélectionnez l'ordre ascending ou descending des données de sortie.
Le tri des colonnes dynamiques ne fonctionne que lorsque le type de tri est configuré en alpha.
-
Pour visionner les données de sortie sous forme de tableau dans la console Run, double-cliquez sur le composant tLogRow et sélectionnez l'option Table dans l'onglet Basic settings.
-
Double-cliquez sur le composant tFileOutputDelimited pour afficher l'onglet Basic settings.

-
Cliquez sur le bouton [...] à côté du champ File name afin de parcourir et sélectionner le répertoire dans lequel vous souhaitez enregistrer le fichier de sortie, puis donnez-lui un nom.
-
Cochez la case Include Header pour récupérer les noms des colonnes ainsi que les données triées.
-
Enregistrez votre Job et appuyez sur F6 pour l'exécuter.
Le résultat de l'opération de tri s'affiche dans la console Run et est écrit dans le fichier de sortie.
Cette page vous a-t-elle aidé ?
Si vous rencontrez des problèmes sur cette page ou dans son contenu – une faute de frappe, une étape manquante ou une erreur technique – dites-nous comment nous améliorer !