
Trier des données
Ce scénario décrit un Job à trois composants. Un composant tRowGenerator est utilisé pour créer des entrées de façon aléatoire. Ces entrées seront ensuite envoyées au composant tSortRow afin d'être triées selon une valeur définie. Dans ce scénario, le flux d'entrée contient des noms de vendeurs ainsi que leur volume de vente respectif et leur nombre d'années d'ancienneté dans l'entreprise. Le résultat de l'opération de tri est affiché dans la console Run.
Pour plus de technologies supportées par Talend, consultez Composants Talend.
-
Déposez les trois composants requis pour ce scénario : tRowGenerator, tSortRow et tLogRow de la Palette dans l'espace de modélisation graphique.
-
Connectez-les à l'aide de liens de type Row Main.
-
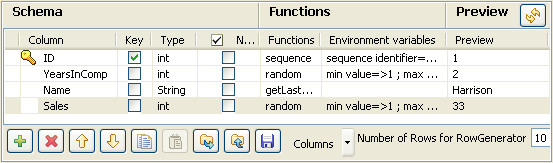
Dans l'éditeur RowGenerator, définissez les valeurs qui seront créées de manière aléatoire et qui seront ensuite triées par le tSortRow. Pour plus d'informations concernant l'utilisation de composant particulier, consultez tRowGenerator
-
Dans ce scénario, chaque vendeur est classé en fonction de la valeur de ses ventes (Sales) et de son ancienneté dans l'entreprise (YearsInComp).
-
Double-cliquez sur tSortRow pour afficher l'onglet Basic settings. Définissez la priorité de tri sur la valeur des ventes et, en second critère, sur l'ancienneté.

-
Utilisez le bouton [+] pour ajouter le nombre de lignes de critères requis. Paramétrez le type de tri, dans cet exemple, les deux critères sont de type numérique. Enfin, étant donné que la sortie est une classification, définissez l'ordre de tri comme descendant.
-
Dans l'onglet Advanced settings, cochez l'option Sort on disk pour modifier les paramètres de la mémoire temporaire. Dans le champ Temp data directory path, renseignez le chemin d'accès au dossier dans lequel vous voulez stocker les données temporaires. Dans le champ Buffer size of external sort, définissez la taille maximale de la mémoire tampon à allouer au traitement des données.
La valeur par défaut de la mémoire tampon est de 1000000 mais plus vous traitez un nombre important de lignes et/ou colonnes, plus cette valeur devra être élevée pour éviter l'interruption automatique du Job signifiée par le message d'erreur "out of memory".
-
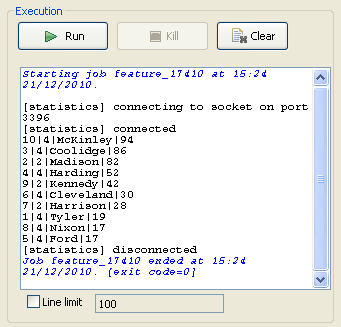
Assurez-vous que ce flux est connecté au composant de sortie tLogRow, afin d'afficher le résultat dans la console du Job.
-
Appuyez sur F6 pour exécuter le Job. Le classement est d'abord basé sur la valeur des ventes, puis sur le nombre d'années d'ancienneté.
Cette page vous a-t-elle aidé ?
Si vous rencontrez des problèmes sur cette page ou dans son contenu – une faute de frappe, une étape manquante ou une erreur technique – dites-nous comment nous améliorer !