
Big Data : nouvelles fonctionnalités
Améliorations apportées à la conception de Jobs Spark
|
Fonctionnalité |
Description |
Disponible dans |
|---|---|---|
| ADLS Gen2 | Azure Data Lake Storage Generation2 est à présent supporté avec les plateformes Big Data suivantes :
|
Tous les produits Talend incluant Big Data |
| Snowflake | Les composants Snowflake pour Spark Batch sont à présent généralement disponibles. |
Tous les produits Talend incluant Big Data |
| Jeux de données natifs |
Dans les Jobs Spark Batch, le support des jeux de données Spark natifs a été ajouté à d'autres composants, afin d'obtenir de meilleures performances. Pour bénéficier de cette amélioration, les utilisateurs et utilisatrices doivent utiliser Spark V2.0 ou supérieure avec les composants suivants :
Les composants suivants nécessitent Spark V2.1 ou supérieure pour supporter les jeux de données Spark.
|
Tous les produits Talend incluant Big Data |
| Delta Lake | Les composants tDeltaLakeInput et tDeltaLakeOutput sont à présent généralement disponibles.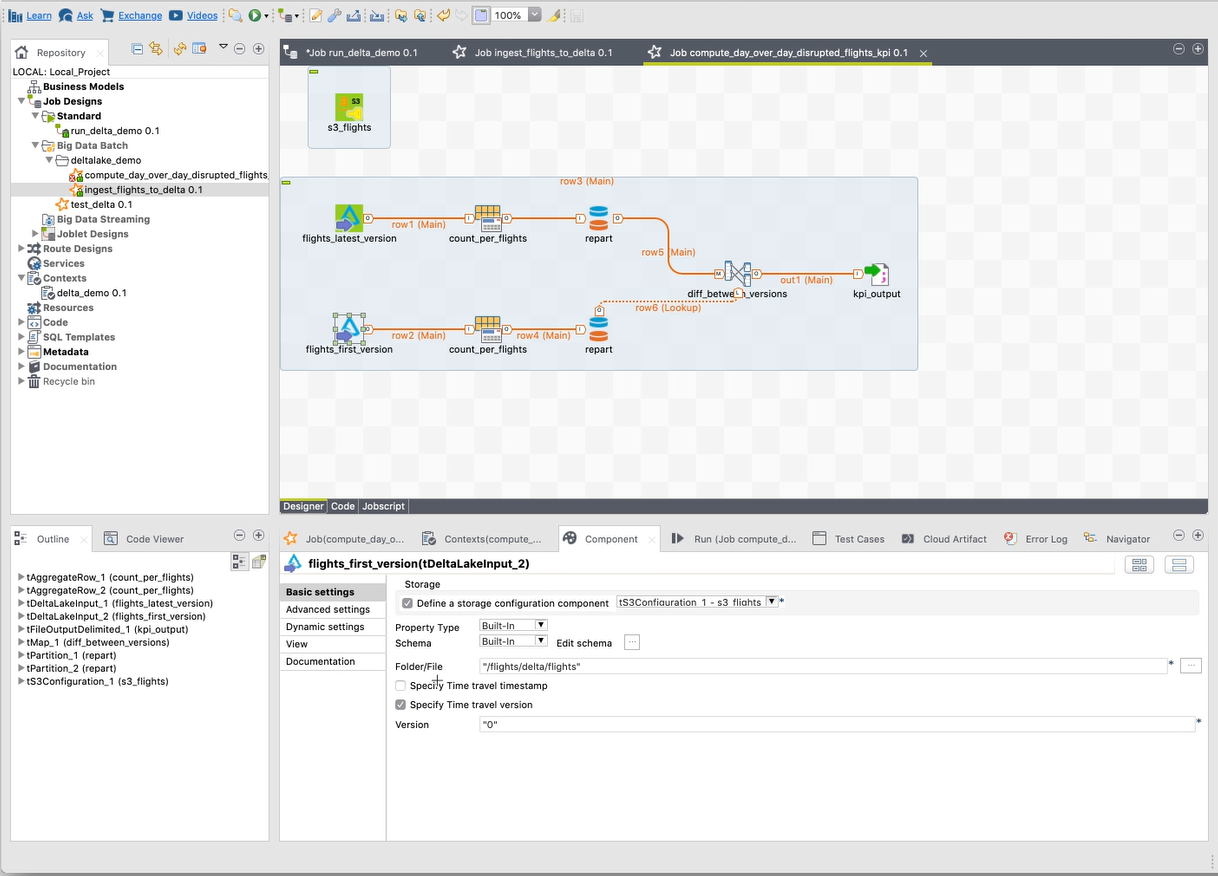
|
Tous les produits Talend incluant Big Data |
| Apache Spark V2.4 | Cette nouvelle version d'Aparch Spark est supportée avec plus de plateformes Big Data dans des Jobs Spark Batch et Spark Streaming. Les plateformes supportant Spark V2.4 sont :
|
Tous les produits Talend incluant Big Data |
| Statut du Job | Avec Databricks, les utilisateurs et utilisatrices peuvent configurer la fréquence à laquelle le Studio demande au cluster Spark le statut des Jobs. |
Tous les produits Talend incluant Big Data |
| tS3Configuration | Avec Amazon EMR, les utilisateurs et utilisatrices peuvent appliquer une politique de bucket S3. |
Tous les produits Talend incluant Big Data |
| tAggregateRow | Dans les Jobs Spark Batch, la fonction de compte distinct (Count) et la fonction Sample Standard Deviation Algorithm function ont été ajoutées. |
Tous les produits Talend incluant Big Data |
| Nouvelles versions des pilotes |
Le support des versions suivantes des pilotes a été ajouté dans les composants associés :
|
Tous les produits Talend incluant Big Data |
|
Nouveaux composants disponibles |
Deux nouveaux composants sont disponibles : le tAzureAdlsGen2Input et le tAzureAdlsGen2Output. |
Tous les produits Talend incluant Big Data |
Support des plateformes Big Data
|
Fonctionnalité |
Description |
Disponible dans |
|---|---|---|
| Databricks |
|
Tous les produits Talend incluant Big Data |
| Hortonworks Data Platform |
|
Tous les produits Talend incluant Big Data |
|
Google Cloud Dataproc |
|
Tous les produits Talend incluant Big Data |
| Configurations Hadoop personnalisées | Lorsqu'ils définissent des connexions à Cloudera ou Hortonworks dans le Repository, les utilisateurs et utilisatrices peuvent à présent spécifier un fichier Jar personnalisé fournissant les paramètres de connexion à l'environnement Hadoop à utiliser. |
Tous les produits Talend incluant Big Data |
Autres composants
|
Fonctionnalité |
Description |
Disponible dans |
|---|---|---|
| Kafka | Kafka V2.2.1 est à présent officiellement supporté avec :
|
Tous les produits Talend incluant Big Data |
| Google BigQuery |
|
Tous les produits Talend incluant Big Data |
| Couchbase |
|
Tous les produits Talend incluant Big Data |
|
CXF |
CXF V3.3.4 est à présent supporté dans les composants suivants :
|
Tous les produits Talend incluant Big Data |
|
MongoDB |
Le support de MongoDB V4.2.x a été ajouté aux composants MongoDB dans les Jobs Standard. |
Tous les produits Talend incluant Big Data |
Cette page vous a-t-elle aidé ?
Si vous rencontrez des problèmes sur cette page ou dans son contenu – une faute de frappe, une étape manquante ou une erreur technique – dites-nous comment nous améliorer !